 Dudochkin Victor
Dudochkin Victor
Анатомия двоичного исполняемого файла
Перевод | Автор оригинала: Matt Oswalt
Несмотря на то, что я занимаюсь разработкой программного обеспечения уже несколько лет, я всегда думал об одном вопросе, и до сих пор у меня не было ни времени, ни терпения, чтобы ответить на него: что такое бинарный исполняемый файл в любом случае? ?
Для этого примера я написал очень простую программу на Rust, которая включает функцию «sum» для сложения двух целых чисел, и я вызываю ее из main():
fn main() {
println!("{}", sum(5, 8));
}
pub fn sum(a: i32, b: i32) -> i32 {
a + b
}
Мой код на Rust всегда структурирован по принципу Cargo, поэтому я могу скомпилировать свою программу, запустив сборку Cargo, и это создаст для меня двоичный файл в каталоге target / debug /. Я назвал свой крэйт rbin, так что это имя двоичного файла, который создается в этом месте:
~$ cargo build
Compiling rbin v0.1.0 (/home/mierdin/Code/rbin)
Finished dev [unoptimized + debuginfo] target(s) in 0.15s
~$ ls -lha target/debug/rbin
-rwxrwxr-x 2 mierdin mierdin 3.1M Nov 3 22:46 target/debug/rbin
В наши дни действительно легко принимать такие вопросы как должное, но если вам интересно, вы можете спросить:
"Но что это за файл?"
Я имею в виду, что мы все обычно знаем, что это «исполняемый файл», поскольку мы его запускаем, и наша программа выполняется. Но что это значит? Что содержится в этом файле, что означает, что наш компьютер автоматически просто знает, как его запустить? И как это возможно, что программа с 7 строками кода может занимать более 3 мегабайт дискового пространства?!?
Оказывается, чтобы создать исполняемый файл для этой до смешного простой программы, компилятор Rust должен включать в себя довольно много дополнительного программного обеспечения, чтобы это стало возможным.
Форматы файлов и заголовки файлов
Что ж, оказывается, существует широко распространенный формат для этих вещей, называемый «Executable and Linkable Format» или ELF!
Обратите внимание, что я не буду здесь всесторонне описывать ELF (есть много других ресурсов, многие из которых я буду ссылаться) - скорее, это исследование того, что входит в двоичный файл Rust с простейшими настройками по умолчанию и некоторыми наблюдения по поводу того, что мне кажется интересным.
ELF - широко известный и популярный формат, особенно в мире Linux, но есть и другие. Операционные системы, такие как Windows и macOS, имеют свой собственный формат, и это большая причина, по которой при компиляции (или просто загрузке) программного обеспечения вы должны указать операционную систему, в которой вы хотите его запустить. Это верно, несмотря на то, что базовый машинный код, который выполняет вашу программу, может быть одинаковым на всех из них (например, x86_64).
Исключительный визуальный фрагмент формата ELF можно найти по ссылке на страницу википедии ELF выше, я обнаружил, что постоянно возвращаюсь к нему, когда пишу этот пост:
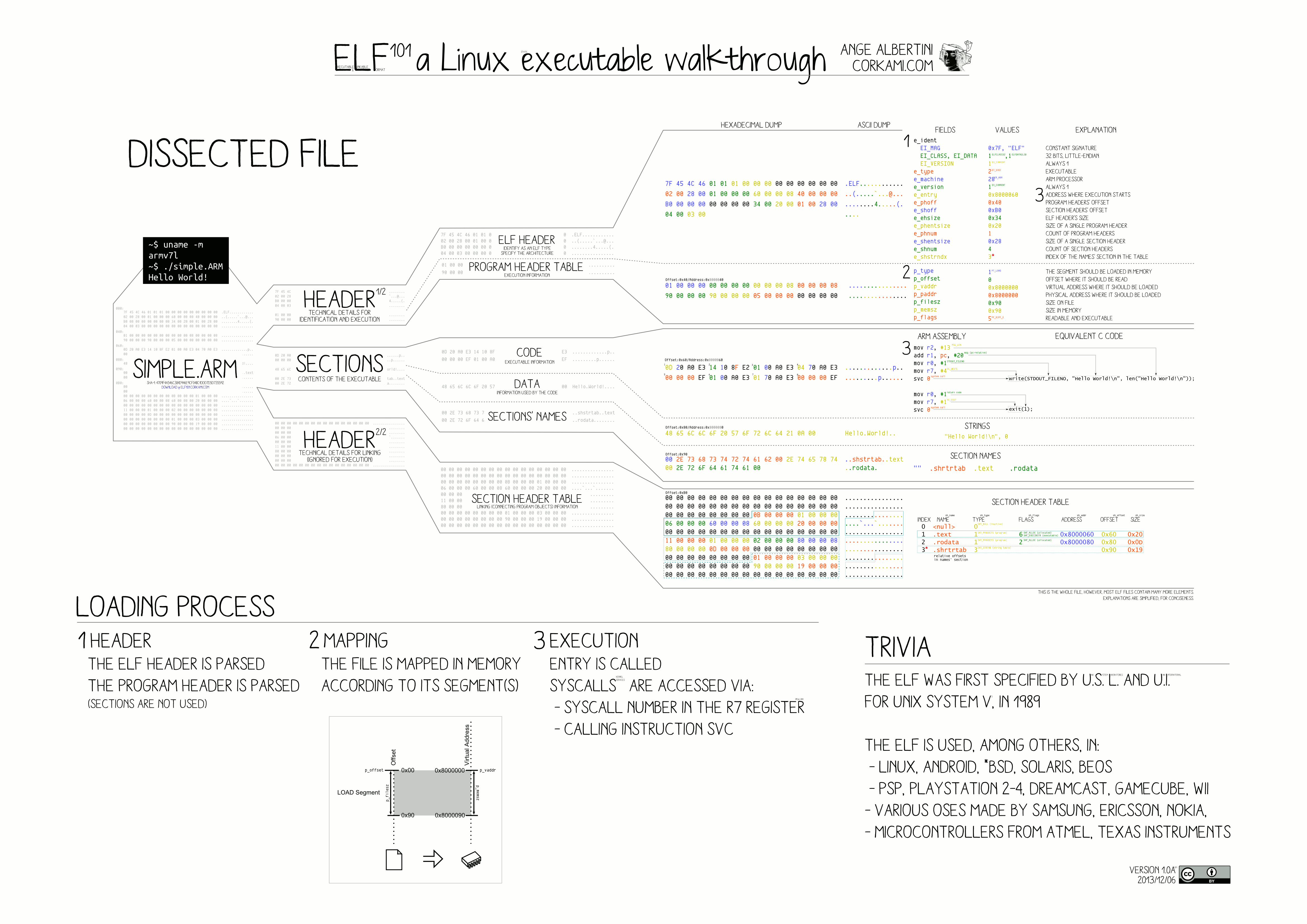
Обычно исполняемые форматы, подобные этому, указывают магическое число в самом начале файла, чтобы формат можно было легко идентифицировать. Он занимает первые четыре байта в заголовке файла. Это очень важное поле, потому что до тех пор, пока мы не сможем правильно идентифицировать файл ELF, мы не можем ожидать, что с ним сделаем что-нибудь «ELF-y». Мы знаем, где должны быть определенные биты информации в файле ELF, но сначала мы должны определить, используя эти байты, что это то, чего мы можем ожидать.
Утилита readelf чрезвычайно полезна для печати всех видов полезных метаданных и связанных таблиц информации, содержащихся в файле ELF. Однако эта утилита ожидает - естественно, - что читаемый файл на самом деле является файлом ELF, и даже дает полезную подсказку о том, что ожидаемые «магические байты» для файла, отличного от ELF, не установлены должным образом при использовании с файлом, отличным от ELF. файл, поэтому он не пытается прочитать остальное:
~$ readelf -l .gitignore
readelf: Error: Not an ELF file - it has the wrong magic bytes at the start
После идентификации весь остальной файл может быть идентифицирован с помощью байтовых смещений (то есть количества байтов от нуля).
Для тех, кто привык смотреть на захват сетевых пакетов, все это должно показаться вам очень знакомым, поскольку именно так мы узнаем, где расположены определенные поля в заголовке пакета. Кадры Ethernet имеют предсказуемую преамбулу и ограничитель начала кадра. В Ethernet также есть поле, называемое «Ethertype», которое дает представление о том, какой протокол содержится в кадре Ethernet (что позволяет компьютерам также анализировать это поле). Так же, как Ethernet имеет стандартный набор байтовых смещений, которые указывают, где должны быть представлены различные поля, формат ELF определяет свои собственные смещения для всех полей, предоставляя полезную идентификационную информацию и информацию о выполнении в заголовке файла, который затем указывает на другие важные места. внутри файла.
В этом заголовке содержится вся полезная информация, но, в частности, поле e_entry в заголовке файла указывает на место смещения, с которого должно начинаться выполнение. Это «точка входа» для программы. Мы определенно будем немного следить за этим в кроличьей норе.
Мы снова можем использовать readelf, на этот раз для правильного файла ELF (наша программа на Rust), а также использовать флаг -h для отображения заголовка файла:
~$ readelf -h target/debug/rbin
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: DYN (Shared object file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x5070
Start of program headers: 64 (bytes into file)
Start of section headers: 3195368 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 12
Size of section headers: 64 (bytes)
Number of section headers: 42
Section header string table index: 41
Итак, «магическое число» позволяет нам анализировать, по крайней мере, остальную часть заголовка файла, которая содержит не только информацию о файле, но и расположение байтовых смещений для других важных частей файла. Один из них - «Начало заголовков программы», которое начинается после 64 байтов.
Заголовки программ
Таблица заголовка программы содержит информацию, которая позволяет операционной системе выделить память и загрузить программу. Это также называется образом процесса. Вы можете думать об этом как о списке «инструкций», которые говорят системе выполнять различные действия с фрагментами памяти, чтобы подготовиться к выполнению этой программы.
Утилита readelf также позволяет нам читать заголовки программ с помощью флага -l:
~$ readelf -l target/debug/rbin
Elf file type is DYN (Shared object file)
Entry point 0x5070
There are 12 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000000040 0x0000000000000040 0x0000000000000040
0x00000000000002a0 0x00000000000002a0 R 0x8
INTERP 0x00000000000002e0 0x00000000000002e0 0x00000000000002e0
0x000000000000001c 0x000000000000001c R 0x1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000004ed8 0x0000000000004ed8 R 0x1000
LOAD 0x0000000000005000 0x0000000000005000 0x0000000000005000
0x0000000000030571 0x0000000000030571 R E 0x1000
LOAD 0x0000000000036000 0x0000000000036000 0x0000000000036000
0x000000000000be44 0x000000000000be44 R 0x1000
LOAD 0x0000000000042520 0x0000000000043520 0x0000000000043520
0x0000000000002b18 0x0000000000002cf8 RW 0x1000
DYNAMIC 0x0000000000044740 0x0000000000045740 0x0000000000045740
0x0000000000000230 0x0000000000000230 RW 0x8
NOTE 0x00000000000002fc 0x00000000000002fc 0x00000000000002fc
0x0000000000000044 0x0000000000000044 R 0x4
TLS 0x0000000000042520 0x0000000000043520 0x0000000000043520
0x0000000000000000 0x00000000000000d8 R 0x20
GNU_EH_FRAME 0x000000000003aa8c 0x000000000003aa8c 0x000000000003aa8c
0x0000000000000d84 0x0000000000000d84 R 0x4
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 0x10
GNU_RELRO 0x0000000000042520 0x0000000000043520 0x0000000000043520
0x0000000000002ae0 0x0000000000002ae0 R 0x1
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.gnu.build-id .note.ABI-tag .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt
03 .init .plt .plt.got .text .fini
04 .rodata .debug_gdb_scripts .eh_frame_hdr .eh_frame .gcc_except_table
05 .init_array .fini_array .data.rel.ro .dynamic .got .data .bss
06 .dynamic
07 .note.gnu.build-id .note.ABI-tag
08 .tbss
09 .eh_frame_hdr
10
11 .init_array .fini_array .data.rel.ro .dynamic .got
Каждый тип заголовка программы делает что-то свое с фрагментом памяти (сегментом). Рядом с каждым заголовком можно найти два 64-битных (это ведь 64-битный ELF) шестнадцатеричных значений. Как указано в верхней части вывода заголовка, верхнее значение - это смещение в памяти сегмента, на который ссылается заголовок (где он расположен). Значение ниже - это размер этого конкретного сегмента в файле.
Каждый сегмент подразделяется на разделы, о которых мы поговорим позже. А пока обратите внимание на таблицу «сопоставление разделов с сегментами» под заголовками программ. Видите, как они пронумерованы? Эти числа соответствуют положению заголовков программы выше. Итак, первый заголовок (который имеет тип PHDR) относится к сегменту 00, второй (который оказывается INTERP) - к 01 и так далее.
Полный обзор типов заголовков программы можно найти здесь, но краткое объяснение каждого сегмента нашей фактической программы и того, что указывает соответствующий тип заголовка, следует делать с этим сегментом, можно найти ниже:
| Segment Number | Header Type | Explanation |
|---|---|---|
| 00 | PHDR | Указывает расположение и размер самой таблицы заголовков программы |
| 01 | INTERP | Указывает расположение интерпретатора в системе, используемого для динамического связывания. Это позволяет нам просто использовать библиотеки в системе, вместо того, чтобы компилировать все эти библиотеки в двоичный файл (это называется статической компоновкой). |
| 02-05 | LOAD | Эти сегменты загружаются в память. Обратите внимание, что в сегменте 03 установлен флаг E, который указывает, что именно здесь находится наш исполняемый код. |
| 06 | DYNAMIC | Предоставляет информацию о динамической компоновке, например о том, какие библиотеки в системе интерпретатор должен предоставить доступ во время выполнения. |
| 07 | NOTE | Это обычно используется для хранения таких вещей, как ABI (и версия), используемые в этой программе для связи с базовой операционной системой. |
| 08 | TLS | Локальное хранилище потока |
| 09 | GNU_EH_FRAME | Кадр раскрутки информации. Используется для обработки исключений |
| 10 | GNU_STACK | Используется для явного запроса на выполнение стека (обратите внимание на вывод выше, этот бит не установлен) |
| 11 | GNU_RELRO | Задает область памяти, которая должна быть доступна только для чтения после загрузки (перемещения). |
Теперь мы лучше понимаем, что, по мнению компилятора Rust, должно быть включено в таблицу заголовков программы - в частности, как Rust рекомендует, чтобы наш компьютер готовился к запуску скомпилированной программы - опять же, в простейшем случае по умолчанию. Некоторые выводы из этого:
- Обратите внимание, что в выводе readelf, когда мы увидели тип заголовка INTERP для сегмента 01, мы увидели предварительный просмотр запрашиваемого интерпретатора, /lib64/ld-linux-x86-64.so.2. Вы можете запустить его самостоятельно, и он немного расскажет вам о себе. Довольно круто!
- Наличие типов заголовков INTERP и DYNAMIC подразумевает, что динамическое связывание используется по умолчанию при компиляции программ на Rust, что не странно - многие скомпилированные языки заставляют вас указывать, хотите ли вы статически связанный двоичный файл.
Таблица заголовков разделов
Таблица заголовков разделов обычно находится ближе к концу файла ELF, и ее основная задача - предоставлять информацию для целей связывания, но я также счел полезным понять содержимое каждого раздела - в частности, размер каждого:
~$ readelf -S target/debug/rbin
There are 42 section headers, starting at offset 0x30c1e8:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .interp PROGBITS 00000000000002e0 000002e0
000000000000001c 0000000000000000 A 0 0 1
[ 2] .note.gnu.build-i NOTE 00000000000002fc 000002fc
0000000000000024 0000000000000000 A 0 0 4
[ 3] .note.ABI-tag NOTE 0000000000000320 00000320
0000000000000020 0000000000000000 A 0 0 4
[ 4] .gnu.hash GNU_HASH 0000000000000340 00000340
0000000000000024 0000000000000000 A 5 0 8
[ 5] .dynsym DYNSYM 0000000000000368 00000368
0000000000000720 0000000000000018 A 6 1 8
[ 6] .dynstr STRTAB 0000000000000a88 00000a88
000000000000052d 0000000000000000 A 0 0 1
[ 7] .gnu.version VERSYM 0000000000000fb6 00000fb6
0000000000000098 0000000000000002 A 5 0 2
[ 8] .gnu.version_r VERNEED 0000000000001050 00001050
00000000000000f0 0000000000000000 A 6 4 8
[ 9] .rela.dyn RELA 0000000000001140 00001140
0000000000003d50 0000000000000018 A 5 0 8
[10] .rela.plt RELA 0000000000004e90 00004e90
0000000000000048 0000000000000018 AI 5 26 8
[11] .init PROGBITS 0000000000005000 00005000
000000000000001b 0000000000000000 AX 0 0 4
[12] .plt PROGBITS 0000000000005020 00005020
0000000000000040 0000000000000010 AX 0 0 16
[13] .plt.got PROGBITS 0000000000005060 00005060
0000000000000008 0000000000000008 AX 0 0 8
[14] .text PROGBITS 0000000000005070 00005070
00000000000304f3 0000000000000000 AX 0 0 16
[15] .fini PROGBITS 0000000000035564 00035564
000000000000000d 0000000000000000 AX 0 0 4
[16] .rodata PROGBITS 0000000000036000 00036000
0000000000004a69 0000000000000000 A 0 0 16
[17] .debug_gdb_script PROGBITS 000000000003aa69 0003aa69
0000000000000022 0000000000000001 AMS 0 0 1
[18] .eh_frame_hdr PROGBITS 000000000003aa8c 0003aa8c
0000000000000d84 0000000000000000 A 0 0 4
[19] .eh_frame PROGBITS 000000000003b810 0003b810
00000000000049e0 0000000000000000 A 0 0 8
[20] .gcc_except_table PROGBITS 00000000000401f0 000401f0
0000000000001c54 0000000000000000 A 0 0 4
[21] .tbss NOBITS 0000000000043520 00042520
00000000000000d8 0000000000000000 WAT 0 0 32
[22] .init_array INIT_ARRAY 0000000000043520 00042520
0000000000000010 0000000000000008 WA 0 0 8
[23] .fini_array FINI_ARRAY 0000000000043530 00042530
0000000000000008 0000000000000008 WA 0 0 8
[24] .data.rel.ro PROGBITS 0000000000043538 00042538
0000000000002208 0000000000000000 WA 0 0 8
[25] .dynamic DYNAMIC 0000000000045740 00044740
0000000000000230 0000000000000010 WA 6 0 8
[26] .got PROGBITS 0000000000045970 00044970
0000000000000678 0000000000000008 WA 0 0 8
[27] .data PROGBITS 0000000000046000 00045000
0000000000000038 0000000000000000 WA 0 0 8
[28] .bss NOBITS 0000000000046038 00045038
00000000000001e0 0000000000000000 WA 0 0 8
[29] .comment PROGBITS 0000000000000000 00045038
000000000000002a 0000000000000001 MS 0 0 1
[30] .debug_aranges PROGBITS 0000000000000000 00045062
0000000000008700 0000000000000000 0 0 1
[31] .debug_pubnames PROGBITS 0000000000000000 0004d762
00000000000479a9 0000000000000000 0 0 1
[32] .debug_info PROGBITS 0000000000000000 0009510b
00000000000ba088 0000000000000000 0 0 1
[33] .debug_abbrev PROGBITS 0000000000000000 0014f193
000000000000102c 0000000000000000 0 0 1
[34] .debug_line PROGBITS 0000000000000000 001501bf
000000000005f7cd 0000000000000000 0 0 1
[35] .debug_frame PROGBITS 0000000000000000 001af990
00000000000001f0 0000000000000000 0 0 8
[36] .debug_str PROGBITS 0000000000000000 001afb80
00000000000ce162 0000000000000001 MS 0 0 1
[37] .debug_pubtypes PROGBITS 0000000000000000 0027dce2
000000000000068b 0000000000000000 0 0 1
[38] .debug_ranges PROGBITS 0000000000000000 0027e36d
000000000007e400 0000000000000000 0 0 1
[39] .symtab SYMTAB 0000000000000000 002fc770
00000000000055f8 0000000000000018 40 642 8
[40] .strtab STRTAB 0000000000000000 00301d68
000000000000a2cb 0000000000000000 0 0 1
[41] .shstrtab STRTAB 0000000000000000 0030c033
00000000000001b1 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
l (large), p (processor specific)
Если вы преобразуете размер каждого раздела из шестнадцатеричного в десятичный и сложите их, вы получите 3190428 (байтов), что действительно близко к общему размеру файла 3198056, как сообщает ls. Итак, с помощью этой таблицы разделов мы можем начать понимать, откуда берутся все эти данные, и понимать, где искать дальше.
Я оставлю это здесь пока, но этот урок дает действительно хороший обзор этой таблицы.
Раздел выполнения
Ну что теперь? Что на самом деле выполняется?
Хотя у readelf есть несколько флагов для проверки содержимого этих разделов, вместо этого мы будем использовать инструмент под названием objdump, который намного лучше показывает разбивку содержимого каждого раздела как в необработанных шестнадцатеричных кодах операций и аргументах, так и в интерпретируемая сборка:
objdump -d -C target/debug/rbin -EL -M intel --insn-width=8 | less
Некоторые указатели на флаги, которые я передаю:
- Флаг -d указывает objdump дизассемблировать все исполняемые разделы. Это приведет к созданию инструкций по сборке рядом с соответствующим машинным кодом на выходе.
- -C target / debug / rbin указывает на расположение двоичного файла для дизассемблирования.
- -M Intel указывает, что формат Intel следует использовать при интерпретации машинного кода и отображении в сборке.
- --insn-width = 8 - это эстетическое предпочтение для меня - мне нравится, чтобы машинный код отображался в одной строке, и иногда он может быть длиной 8 байт (по умолчанию 7)
- Остальные | less направляет вывод в less, что позволяет мне просматривать вывод с помощью клавиш со стрелками, перемещаться вверх и вниз и с легкостью выполнять поиск.
Флаг -S чередует исходный код Rust внутри сборки, поэтому мы можем точно видеть, какие строки Rust привели к каким строкам машинного кода. Я пропустил это, потому что я сам буду объяснять соответствующие строки, и это делает примеры более простыми, но определенно используйте этот флаг самостоятельно, так как это было очень полезно для меня.
В заголовке файла мы видели ссылку на точку входа в память. Напоминаем, что это был 0x5070. После того, как заголовок файла и заголовки программы будут проанализированы и сегменты загружены в память, компьютер начнет выполнение инструкций, начиная с этой позиции. Итак, давайте перейдем к этой позиции в выводе objdump и будем использовать ее в качестве отправной точки. Обратите внимание, что это можно найти в разделе .text, который мы только что рассмотрели:
Разборка раздела .text:
0000000000005070 <_start>:
5070: f3 0f 1e fa endbr64
5074: 31 ed xor ebp,ebp
5076: 49 89 d1 mov r9,rdx
5079: 5e pop rsi
507a: 48 89 e2 mov rdx,rsp
507d: 48 83 e4 f0 and rsp,0xfffffffffffffff0
5081: 50 push rax
5082: 54 push rsp
5083: 4c 8d 05 b6 04 03 00 lea r8,[rip+0x304b6] # 35540 <__libc_csu_fini>
508a: 48 8d 0d 3f 04 03 00 lea rcx,[rip+0x3043f] # 354d0 <__libc_csu_init>
5091: 48 8d 3d 38 03 00 00 lea rdi,[rip+0x338] # 53d0 <main>
5098: ff 15 92 0b 04 00 call QWORD PTR [rip+0x40b92] # 45c30 <__libc_start_main@GLIBC_2.2.5>
509e: f4 hlt
509f: 90 nop
В среднем столбце (начиная с endbr64) показана инструкция x86_64, выполняемая в этой строке. Крайний правый столбец содержит параметры для каждой из этих операций. Ближе к концу мы видим, что компилятор Rust предоставил несколько полезных подсказок о том, куда будет двигаться выполнение дальше. По адресу 0x5091 мы видим инструкцию с интересным комментарием справа: # 53d0
00000000000053d0 <main>:
53d0: 48 83 ec 18 sub rsp,0x18
53d4: 8a 05 8f 56 03 00 mov al,BYTE PTR [rip+0x3568f] # 3aa69 <__rustc_debug_gdb_scripts_section__>
53da: 48 63 cf movsxd rcx,edi
53dd: 48 8d 3d 0c ff ff ff lea rdi,[rip+0xffffffffffffff0c] # 52f0 <rbin::main>
53e4: 48 89 74 24 10 mov QWORD PTR [rsp+0x10],rsi
53e9: 48 89 ce mov rsi,rcx
53ec: 48 8b 54 24 10 mov rdx,QWORD PTR [rsp+0x10]
53f1: 88 44 24 0f mov BYTE PTR [rsp+0xf],al
53f5: e8 e6 fd ff ff call 51e0 <std::rt::lang_start>
53fa: 48 83 c4 18 add rsp,0x18
53fe: c3 ret
53ff: 90 nop
Опять же, у нас есть еще одна подсказка: # 52f0 rbin::main. На этот раз мы прокручиваем вверх, чтобы найти этот адрес и, в свою очередь, фактический машинный код, представляющий нашу функцию main():
00000000000052f0 <rbin::main>:
52f0: 48 83 ec 78 sub rsp,0x78
52f4: 48 8b 05 8d e2 03 00 mov rax,QWORD PTR [rip+0x3e28d] # 43588 <__do_global_dtors_aux_fini_array_entry+0>
52fb: bf 05 00 00 00 mov edi,0x5
5300: be 08 00 00 00 mov esi,0x8
5305: 48 89 44 24 18 mov QWORD PTR [rsp+0x18],rax
530a: e8 81 00 00 00 call 5390 <rbin::sum>
530f: 89 44 24 6c mov DWORD PTR [rsp+0x6c],eax
5313: 48 8d 35 46 f4 02 00 lea rsi,[rip+0x2f446] # 34760 <core::fmt::num::imp::<impl core::fmt::Display for >
531a: 48 8d 44 24 6c lea rax,[rsp+0x6c]
531f: 48 89 44 24 60 mov QWORD PTR [rsp+0x60],rax
5324: 48 8b 44 24 60 mov rax,QWORD PTR [rsp+0x60]
5329: 48 89 44 24 70 mov QWORD PTR [rsp+0x70],rax
532e: 48 89 c7 mov rdi,rax
5331: e8 4a fe ff ff call 5180 <core::fmt::ArgumentV1::new>
5336: 48 89 44 24 10 mov QWORD PTR [rsp+0x10],rax
533b: 48 89 54 24 08 mov QWORD PTR [rsp+0x8],rdx
5340: 48 8b 44 24 10 mov rax,QWORD PTR [rsp+0x10]
5345: 48 89 44 24 50 mov QWORD PTR [rsp+0x50],rax
534a: 48 8b 4c 24 08 mov rcx,QWORD PTR [rsp+0x8]
534f: 48 89 4c 24 58 mov QWORD PTR [rsp+0x58],rcx
5354: 48 8d 54 24 50 lea rdx,[rsp+0x50]
5359: 48 8d 7c 24 20 lea rdi,[rsp+0x20]
535e: 48 8b 74 24 18 mov rsi,QWORD PTR [rsp+0x18]
5363: 41 b8 02 00 00 00 mov r8d,0x2
5369: 48 89 14 24 mov QWORD PTR [rsp],rdx
536d: 4c 89 c2 mov rdx,r8
5370: 48 8b 0c 24 mov rcx,QWORD PTR [rsp]
5374: 41 b8 01 00 00 00 mov r8d,0x1
537a: e8 c1 00 00 00 call 5440 <core::fmt::Arguments::new_v1>
537f: 48 8d 7c 24 20 lea rdi,[rsp+0x20]
5384: ff 15 16 0b 04 00 call QWORD PTR [rip+0x40b16] # 45ea0 <_GLOBAL_OFFSET_TABLE_+0x530>
538a: 48 83 c4 78 add rsp,0x78
538e: c3 ret
538f: 90 nop
Как вы понимаете, здесь есть о чем рассказать - слишком много, чтобы охватить эту статью. Поэтому вместо этого мы рассмотрим инструкции, которые наиболее актуальны для примера кода в начале этого сообщения. Не стесняйтесь ознакомиться с инструкциями, которые я не раскрываю подробно - я просмотрел и нашел их поучительными.
Если вы новичок в чтении ассемблера, как и я, хорошая новость заключается в том, что существует множество руководств, которые могут помочь вам понять, что здесь происходит. Я нашел это руководство и это резюме полезными, но есть много других, которые тоже работают хорошо - просто помните о синтаксисе сборки, которую вы используете (помните, что я использую Intel для этого сообщения).
Сначала мы замечаем, что в верхней части кода этой функции мы видим, что первая операция требует 120 (0x78) байт пространства стека. Обычно в верхней части блока машинного кода каждой функции можно увидеть:
52f0: 48 83 ec 78 sub rsp,0x78
Напомним, наша программа определяет два целочисленных литерала (5 и 8) в качестве параметров нашей функции суммы, поэтому компилятор Rust перемещает оба этих значения в регистры edi и esi:
52fb: bf 05 00 00 00 mov edi,0x5
5300: be 08 00 00 00 mov esi,0x8
Мы почти готовы вызвать нашу функцию суммы, но прежде чем мы сможем это сделать, нам нужно что-то сделать с регистром rax:
По соглашению% rax используется для хранения возвращаемого значения функции, если оно существует.
Значение, возвращаемое суммой, в конечном итоге будет сохранено в регистре rax, но если вы посмотрите внимательно, мы уже переместили значение в rax в нашей основной функции. Итак, прежде чем мы вызовем сумму, мы должны переместить это значение в безопасное место.
Если %rax содержит значение, которое вызывающий абонент хочет сохранить, вызывающий должен скопировать это значение в «безопасное» место перед выполнением вызова.
Наш компилятор знает, что наша функция суммы будет использовать 18 байтов пространства стека (как мы увидим, когда посмотрим на код функции суммы), поэтому мы можем безопасно переместить это значение в область памяти, которая смещена на 18 байтов от текущий указатель стека:
5305: 48 89 44 24 18 mov QWORD PTR [rsp+0x18],rax #TODO Why does this happen before the function call?
Наконец, мы можем вызвать нашу функцию суммы:
530a: e8 81 00 00 00 call 5390 <rbin::sum>
Давайте посмотрим на эту ячейку памяти (5390) - я снова предоставлю всю сборку для этой функции, а затем подробно изучу соответствующие инструкции:
0000000000005390 <rbin::sum>:
5390: 48 83 ec 18 sub rsp,0x18
5394: 89 7c 24 10 mov DWORD PTR [rsp+0x10],edi
5398: 89 74 24 14 mov DWORD PTR [rsp+0x14],esi
539c: 01 f7 add edi,esi
539e: 0f 90 c0 seto al
53a1: a8 01 test al,0x1
53a3: 89 7c 24 0c mov DWORD PTR [rsp+0xc],edi
53a7: 75 09 jne 53b2 <rbin::sum+0x22>
53a9: 8b 44 24 0c mov eax,DWORD PTR [rsp+0xc]
53ad: 48 83 c4 18 add rsp,0x18
53b1: c3 ret
53b2: 48 8d 3d 57 0c 03 00 lea rdi,[rip+0x30c57] # 36010 <str.0>
53b9: 48 8d 15 d0 e1 03 00 lea rdx,[rip+0x3e1d0] # 43590 <__do_global_dtors_aux_fini_array_entry+0x60>
53c0: 48 8d 05 b9 ad 02 00 lea rax,[rip+0x2adb9] # 30180 <core::panicking::panic>
53c7: be 1c 00 00 00 mov esi,0x1c
53cc: ff d0 call rax
53ce: 0f 0b ud2
Как это было сделано с функцией main() и как уже упоминалось ранее, эта функция выделяет 18 байт пространства стека:
5390: 48 83 ec 18 sub rsp,0x18
Затем мы перемещаем значения в регистры edi и esi, которые, если вы помните из основной функции, хранят параметры для нашей функции суммы. Здесь следует отметить несколько моментов: смещения памяти rsp + 0x10 и rsp + 0x14 находятся в выделенном нами пространстве стека. Фактически, для каждого местоположения достаточно места для хранения 4-байтового значения. Это имеет смысл, потому что оба должны быть именно такими - 32-битными целыми числами!
5394: 89 7c 24 10 mov DWORD PTR [rsp+0x10],edi
5398: 89 74 24 14 mov DWORD PTR [rsp+0x14],esi
Затем мы складываем эти два значения. Эта операция работает путем добавления значения второго операнда к первому, поэтому после завершения этой операции edi больше не будет представлять один из наших параметров, а будет результатом нашей операции сложения:
539c: 01 f7 add edi,esi
Затем мы перемещаем результат этой операции, теперь хранящийся в edi, в пространство стека, а затем снова оттуда в регистр eax
53a3: 89 7c 24 0c mov DWORD PTR [rsp+0xc],edi
53a9: 8b 44 24 0c mov eax,DWORD PTR [rsp+0xc]
Наконец, мы можем вернуть пространство стека и вернуться к месту вызова в основной функции:
53ad: 48 83 c4 18 add rsp,0x18
53b1: c3 ret
Вернемся к нашей основной функции, операции, следующие сразу за нашим вызовом sum, перемещают результат, сохраненный в eax, в пространство стека, а затем оттуда в регистр rax.
530f: 89 44 24 6c mov DWORD PTR [rsp+0x6c],eax # eax is where our sum function placed the result of our addition
5313: 48 8d 35 46 f4 02 00 lea rsi,[rip+0x2f446] # 34760 <core::fmt::num::imp::<impl core::fmt::Display for >
531a: 48 8d 44 24 6c lea rax,[rsp+0x6c]
Это был очень ограниченный взгляд на многочисленные операции, генерируемые компилятором Rust, которые на первый взгляд выглядят очень простой операцией. Представьте, как должно выглядеть сложное приложение! Было множество других случаев, которые мы не рассмотрели, например, те, которые приводят к сбою программы, поэтому, пожалуйста, найдите время, чтобы использовать команды, которые я показал выше, чтобы посмотреть на свой собственный код и изучить его.
Резюме
Это было небольшое путешествие, но, надеюсь, вы продолжили его и узнали столько же, сколько и я! В итоге:
-
Фактический формат исполняемого файла - ELF. Существует много разных форматов, но это очень распространенный в операционных системах на базе Linux. В исполняемом двоичном файле содержится огромное количество метаданных, которые легко проверять с помощью легко доступных инструментов.
-
Фактический машинный код - это машинный код x86. Этот набор команд поддерживается многими аппаратными платформами, и по этой причине считается «аппаратно-независимым». Это просто означает, что этот набор инструкций может использоваться не только на определенном типе оборудования, но и широко принят и поддерживается.
-
Интерпретация двоичных инструкций (как шестнадцатеричных кодов операций) - Intel. Это менее значимо для компьютера и более значимо для меня, поскольку на уровне машинного кода нет «intel vs att». Это всего лишь интерпретация, которая позволяет нам сделать машинный код более читаемым и доступным для записи.
-
Фактический исполняемый код, который помещается в двоичный файл, зависит от компилятора. Как мы видели, даже простой пример приводит к довольно небольшому количеству машинного кода. Мы проделали довольно простую операцию и работали только с выделениями памяти стека, которые довольно хорошо обрабатываются компилятором. Выделение кучи немного сложнее и требует согласования с операционной системой. Вы можете себе представить, что компилятор должен проделать много работы, чтобы просто получить жизнеспособную программу - не говоря уже о дополнительных проверках, которые делает что-то вроде компилятора Rust, чтобы уберечь нас от всех видов проблем с памятью. Попробуйте дизассемблировать более сложную программу и попытаться проследить различные ветви логики через базовую сборку!
Полезные ссылки
Я связался с некоторыми полезными ресурсами в этом посте, но вот несколько других, которые, по моему мнению, были полезными, но не вошли в содержание выше:
- Документациф x86 ABI
- Регистры в x86 ассемблере
- Классный веб-дизассемблер
- Как запускаются программы: двоичные файлы ELF
- Magnifying Glasses для Rust ассемблера
- cargo-asm: подкоманда cargo, которая отображает ассемблер или llvm-ir, сгенерированную для исходного кода Rust.