 Dudochkin Victor
Dudochkin Victor
Распараллеливание Enjarify в Go и Rust
Перевод | Автор оригинала: Robert Grosse
В прошлом году я переписал Enjarify на Go и Rust, чтобы узнать больше о языках и сравнить сложность, многословность, производительность и подверженность ошибкам языков, а также написал сообщение с подробным описанием своих выводов. Для простоты я измерил только однопоточную производительность, но ряд комментаторов посчитали, что это было несправедливо по отношению к Go, потому что простой параллелизм - один из основных аргументов в пользу языка, под которым они предположительно подразумевали параллелизм, не говоря уже о Робе Пайке. Поэтому я решил распараллелить код и написать новый пост с подробным описанием результатов.
Оптимизация
Во-первых, вот показатели производительности из исходного сообщения.
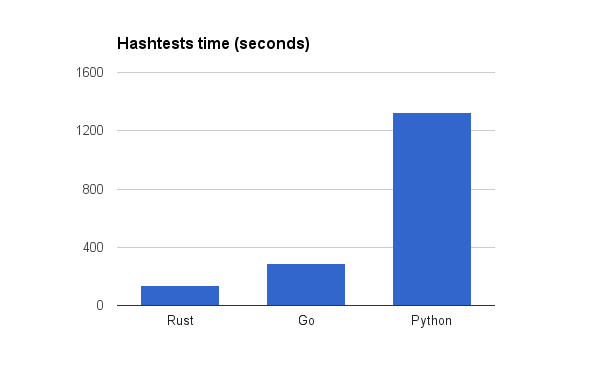
В исходном посте мой код был просто протестирован как есть. Однако при написании версии Rust у меня было несколько идей по оптимизации, которые я хотел попробовать перенести на версию Go, а версия Go также содержала кучу кода, который был написан скорее простым, чем быстрым. Я решил потратить некоторое время на то, чтобы оптимизировать (однопоточный) код Go и Rust, чтобы увидеть, какая разница в производительности является естественной, а не неоптимальной реализацией.
Как оказалось, мне удалось сделать версию Go намного быстрее, хотя и не по тем причинам, которых я ожидал. Например, ручная мономорфизация TreeList привела лишь к небольшому ускорению, а многие микрооптимизации не оказали заметного воздействия или ухудшили положение. Между тем, самое большое улучшение произошло из-за изменения, которое, как я изначально ожидал, замедлит работу. Даже с профилировщиком сложно догадаться, как можно ускорить код, хотя я полагаю, что с опытом это станет проще. Между тем, версия Rust уже была намного быстрее, но я все же смог найти два улучшения.
Кроме того, я также обновил языковые версии, но это имело в основном негативные последствия. CPython поднялся до 3.5.2, что фактически замедлило его примерно на 5%. Обновление до последней версии Rust не дало заметного эффекта. Go 1.8rc1 был примерно на 10% медленнее, поэтому я остановился на 1.7. Обратите внимание, что это только для исходного однопоточного теста - в более поздней параллельной версии не было заметной разницы между 1,7 и 1,8, но я использовал числа 1,7 для согласованности. Большим победителем стал Pypy. В моем предыдущем посте Pypy был опущен из-за того, что он медленнее, чем CPython, но любая ошибка, которая была исправлена за это время, поэтому Pypy теперь включен.
Rust: 82,5 секунды, Go 165 секунд, Pypy 310 секунд, CPython 1402 секунды.
Rust стал на 64% быстрее, а Go стал на 76% быстрее, что снизило соотношение Go / Rust с 2,15 до 2,0. Также интересно, что Pypy был почти таким же быстрым, как неоптимизированная версия Go из исходного сообщения. Это указывает на то, что если Pypy доступен, и вы мало что знаете об оптимизации Go и имеет значение только однопоточная производительность, вы можете не увидеть увеличения скорости от переписывания кода Python в Go, хотя версия Go все равно будет быстрее для краткосрочных задач. из-за отсутствия JIT-разминки.
В любом случае, взяв это за основу, пришло время распараллелить код Go и Rust. Я не стал беспокоиться о версии для Python по понятным причинам.
Дизайн
Первый вопрос при распараллеливании - что и где распараллеливать. К счастью, тест хеш-тестов, который я использовал, уже поразительно параллелен. Он состоит из запуска Enjarify для каждого из 7 тестовых файлов со всеми 256 возможными комбинациями проходов и распечатки хэша вывода. Изначально я создал его для обнаружения непреднамеренных изменений в поведении во время работы над Enjarify, но он также служит удобным автономным тестом.
Очевидным подходом было бы распараллелить цикл хэш-тестов и запустить тесты 1792 параллельно. Однако это выглядело немного искусственно, поскольку не привело бы к каким-либо улучшениям для нормального использования Enjarify. Другое очевидное место для распараллеливания - это основной цикл трансляции, который переводит каждый класс в предоставленном файле (ах) dex в файл классов Java, процесс, который полностью независим от других классов. Нет смысла пытаться распараллелить с более высокой степенью детализации, потому что перевод каждого отдельного класса по своей сути является последовательным из-за того, что все методы и поля в классе совместно используют один пул констант.
Распараллеливание цикла перевода будет хорошо работать при обычном использовании Enjarify, где вы обычно переводите один файл apk с тысячами классов, но не сильно поможет при хэш-тестах, когда один файл с 1–6 классами переводится сотни раз. Поэтому в своих экспериментах я решил, что и цикл хэш-тестов, и цикл трансляции должны быть параллельны.
Идти
Основной примитив параллелизма в Go - это каналы. Фактически, настолько важно, чтобы это был один из трех универсальных типов в языке и имел свой собственный выделенный синтаксис. Стандартная библиотека также предоставляет обычные мьютексы, атомики и т.д., Но я стремился к простейшему и наиболее идиоматическому подходу, а это означало придерживаться каналов.
Очевидный подход - создать горутину для каждой задачи и заставить их всех записывать результат в один канал после завершения. К сожалению, это не работает, потому что результаты будут получены не по порядку. После некоторого исследования того, какие паттерны считаются идиоматическими, я решил использовать паттерн семафорного канала.
Это включает в себя выделение среза для хранения всех результатов заранее и выполнение каждой горутиной записи вывода в заранее определенном месте в этом срезе. Затем они отправляют по каналу тип нулевого размера, чтобы указать завершение. Родительский поток получает по каналу один раз для каждой горутины, а затем читает фрагмент, который теперь содержит весь вывод.
results := [][3]string{}
sem := make(chan struct{}, 9999)
for _, data := range dexs {
dex_ := dex.Parse(data)
n := len(dex_.Classes)
oldlen := len(results)
results = append(results, make([][3]string, n)...)
for i, cls := range dex_.Classes {
go func(cls dex.DexClass, result *[3]string) {
unicode_name := Decode(cls.Name) + ".class"
result[0] = unicode_name
if class_data, err := jvm.ToClassFile(cls, opts); err == nil {
result[1] = class_data
} else {
result[2] = err.Error()
}
sem <- struct{}{}
}(cls, &results[oldlen+i])
}
for i := 0; i < n; i++ {
<-sem
}
}
return results
И, конечно же, я проделал то же самое с циклом хэш-тестов. Это немного сложнее, потому что распечатка хэшей и вычисление окончательного хэша должны выполняться по порядку. Поэтому я разделил цикл на две части - одну, которая выполняет все фактические вычисления, а затем второй цикл, который ожидает, пока это не будет выполнено, и распечатывает результаты по порядку.
sem := make(chan struct{}, 9999)
outputs := [256 * 7][][2]string{}
for test := 1; test < 8; test++ {
name := fmt.Sprintf("test%d", test)
dir := path.Join("..", "tests", name)
rawdex := Read(path.Join(dir, "classes.dex"))
for bits := 0; bits < 256; bits++ {
go func(test, bits int, rawdex string) {
opts := jvm.Options{bits&1 == 1, bits&2 == 2, bits&4 == 4, bits&8 == 8, bits&16 == 16, bits&32 == 32, bits&64 == 64, bits&128 == 128}
results := translate(opts, rawdex)
output := make([][2]string, len(results))
outputs[(test-1)*256+bits] = output
for i := range results {
cls := results[i][1]
util.Assert(cls != "")
output[i][0] = cls
output[i][1] = hash(cls)
}
sem <- struct{}{}
}(test, bits, rawdex)
}
}
for i := 0; i < 7*256; i++ {
<-sem
}
fullhash := ""
for test := 1; test < 8; test++ {
name := fmt.Sprintf("test%d", test)
fmt.Print(name + "\n")
for bits := 0; bits < 256; bits++ {
for _, pair := range outputs[(test-1)*256+bits] {
fmt.Printf("%08b %x\n", uint8(bits), pair[1])
fullhash = hash(fullhash + pair[0])
}
}
}
Rust
В отличие от Go, в Rust параллелизм возлагается на библиотеки. В этом случае я решил использовать Rayon. Прежде чем суслики будут жаловаться, что это несправедливо, я потратил некоторое время на поиски эквивалентных библиотек Go, но не смог их найти.
Rayon выполняет всю буферизацию и упорядочение результатов за вас, поэтому его намного удобнее использовать, чем версию Go. В этом случае большая часть работы была связана с переписыванием моих лупов в стиле iter / map / collect. Как только это было сделано, фактическое распараллеливание сводилось просто к импорту Rayon и изменению iter на par_iter.
let mut results = Vec::new();
for data in dexes.iter() {
let dex = dex::DexFile::new(data);
let dex_classes = dex.parse_classes();
results.extend(dex_classes.par_iter().map(|cls| {
let unicode_name = mutf8::decode(cls.name).into_owned() + ".class";
let res = panic::catch_unwind(panic::AssertUnwindSafe(|| {
Ok(jvm::writeclass::to_class_file(&cls, opts))
})).unwrap_or_else(|err| {
let error_string = err.downcast::<String>().map(|b| *b).or_else(|err| {
err.downcast::<&'static str>().map(|s| s.to_string())
}).unwrap_or("panic with unknown type".to_string());
Err(error_string)
});
(unicode_name, res)
}).collect::<Vec<_>>());
}
results
Код Go также имеет эквивалентный шаблон обработки паники, но он находится в другом месте кода и, следовательно, не показан выше. В общем, я старался сохранить максимально похожий дизайн высокого уровня между тремя версиями.
Как и раньше, мне пришлось разбить цикл на хеш-тесты и поместить операторы печати после того, как были вычислены все результаты. Однако версия Rust потребовала больших изменений, чтобы избавиться от вложенного цикла. Вероятно, есть способ превратить вложенный цикл в итератор, совместимый с Rayon, но мне не хотелось разбираться в этом, поэтому я переписал код с помощью одного цикла итераций 7 * 256, используя модуль для получения исходных индексов. Кроме того, я убрал загрузку тестовых файлов из цикла, чтобы облегчить время жизни.
let testfiles = (1..8).map(|test| read(format!("../tests/test{}/classes.dex", test))).collect::<Vec<_>>();
let outputs: Vec<Vec<(BString, String)>> = (0..(7*256)).into_par_iter().map(|ind| {
let ti = (ind / 256) as usize;
let bits = ind % 256;
let dexes = &testfiles[ti..ti+1];
let results = translate(Options::from(bits as u8), dexes);
let output = results.into_iter().map(|(_, res)| {
let cls = res.unwrap();
let digest = hexdigest(&cls);
(cls, digest)
}).collect();
output
}).collect();
let mut fullhash = vec![];
for (ind, pairs) in outputs.into_iter().enumerate() {
let bits = ind % 256;
if bits==0 {println!("test{}", (ind/256)+1);}
for (cls, digest) in pairs {
println!("{:08b} {}", bits, digest);
fullhash.extend(cls);
fullhash = hash(&fullhash);
}
}
Результаты
На моей 8-ядерной машине (4 физических ядра) результирующий код Go снизился до среднего значения 48,0 секунд, а код Rust снизился до 23,7 секунды. Это означает, что оба имеют ускорение примерно в 3,4 раза. Есть несколько возможных объяснений отсутствия полного масштабирования - закон Амдала, затраты на синхронизацию, конфликты между ядрами в кеш-памяти и т.д., Но я не пытался глубоко исследовать это. Удивительно, что коэффициент ускорения для двух языков примерно одинаков, поскольку нет априорной причины, по которой какой-либо из этих факторов был бы одинаковым в обоих случаях. В любом случае это означает, что код Rust был примерно в два раза быстрее кода Go в каждом тесте - неоптимизированном, оптимизированном и параллельном.
Бонусный раунд - Результаты потоковой передачи
Приведенный выше параллельный код дал хорошее ускорение, но у него есть недостаток, заключающийся в том, что вывод командной строки неинтересен. Последовательная версия распечатывала каждую строку так быстро, как только могла, что приводило к непрерывному потоку результатов, но параллельная версия вообще ничего не распечатывала, пока все не было сделано.
Поэтому я решил посмотреть, смогу ли я это исправить, сохранив параллельные вычисления. Очевидно, что еще должна быть некоторая буферизация, но должна быть возможность распечатать, скажем, первую строку, как только будет готов первый результат, затем дождаться второго результата, если это еще не сделано, и так далее.
Идти
В версии Go реализовать потоковую передачу было легко, хотя для каждой горутины требовался отдельный канал, что выглядело грязным. В соответствии с мантрой Go «разделяйте память посредством общения», я решил создать единственный канал для вывода, с упорядочением, обеспечиваемым передачей этого канала между горутинами через отдельный набор каналов. Каждой горутине передаются два канала, причем выходной конец одного канала подключен к входному концу канала, передаваемому следующей горутине.
outputChan := make(OutputChan)
syncChan := make(chan OutputChan, 1)
syncChan2 := make(chan OutputChan, 1)
syncChan <- outputChan
for test := 1; test < 8; test++ {
name := fmt.Sprintf("test%d", test)
dir := path.Join("..", "tests", name)
rawdex := Read(path.Join(dir, "classes.dex"))
for bits := 0; bits < 256; bits++ {
go func(bits int, rawdex string, inchan <-chan OutputChan, outchan chan<- OutputChan) {
opts := jvm.Options{bits&1 == 1, bits&2 == 2, bits&4 == 4, bits&8 == 8, bits&16 == 16, bits&32 == 32, bits&64 == 64, bits&128 == 128}
results := translate(opts, rawdex)
output := make([][2]string, len(results))
for i := range results {
cls := results[i][1]
util.Assert(cls != "")
output[i][0] = cls
output[i][1] = hash(cls)
}
c := <-inchan
c <- output
outchan <- c
}(bits, rawdex, syncChan, syncChan2)
syncChan = syncChan2
syncChan2 = make(chan OutputChan, 1)
}
}
Цикл перевода в main.go остался нетронутым.
Rust
Стриминг оказался намного сложнее реализовать в версии Rust. Во-первых, Rayon в настоящее время не поддерживает это, поэтому я решил вырвать Rayon и вместо этого попробовать Futures. Я мог бы оставить Rayon для цикла перевода и использовать только футуры для цикла хэш-тестов, но я беспокоился, что наличие нескольких библиотек с независимыми пулами потоков может вызвать проблемы. (По иронии судьбы, оказалось наоборот).
Очевидный способ реализовать потоковую передачу с футурами - создать список футур, каждый из которых представляет одну итерацию цикла. Затем вы просто ждете первого, затем второго и т.д. Это оказалось на самом деле проще, чем я ожидал (бокс не требуется).
В отличие от Rayon, Futures требует, чтобы вы явно создавали пул потоков, а не неявно создавали глобальный пул потоков, но это не имело большого значения. Настоящая проблема заключалась в отсутствии потоков с заданной областью видимости.
Как и большинство библиотек Rust, Rayon и Futures::CpuPool принимают закрытие, которое представляет работу, которую нужно выполнить. В Rayon они имеют ограниченную область видимости - работа гарантированно завершится до того, как вы вернетесь, и, следовательно, замыкания могут безопасно содержать ссылки на стек. Фактически, они могут в основном делать все, что может делать не-закрывающий код в одном и том же месте, а вывод типа замыкания Rust означает, что он просто работает.
К сожалению, Futures этого не поддерживает. CpuPool::spawn_fn() имеет статическую границу, что означает, что переданные замыкания не могут ссылаться на какие-либо данные стека, так как они думают, что они могут пережить порождающий поток.
Для внешнего цикла хеш-тестов это было несложно. Я просто засунул пул и тестовые файлы в Arcs. Однако мне потребовалось время, чтобы придумать подходящий способ клонирования и перемещения их в закрытие, поскольку сообщение об ошибке rustc в этом случае совершенно бесполезно.
let pool = Arc::new(CpuPool::new_num_cpus());
let testfiles = (1..8).map(|test| read(format!("../tests/test{}/classes.dex", test))).collect::<Vec<_>>();
let testfiles = Arc::new(testfiles);
let output_futures: Vec<_> = (0..(7*256)).into_iter().map(|ind| {
let testfiles = testfiles.clone();
let pool2 = pool.clone();
pool.spawn_fn(move || {
let ti = (ind / 256) as usize;
let bits = ind % 256;
let dexes = &testfiles[ti..ti+1];
let results = translate(&pool2, Options::from(bits as u8), dexes);
let output = results.into_iter().map(|(_, res)| {
let cls = res.unwrap();
let digest = hexdigest(&cls);
(cls, digest)
}).collect();
let res: Result<Vec<_>,()> = Ok(output);
res
})
}).collect();
let mut fullhash = vec![];
for (ind, fut) in output_futures.into_iter().enumerate() {
let bits = ind % 256;
if bits==0 {println!("test{}", (ind/256)+1);}
let pairs = fut.wait().unwrap();
for (cls, digest) in pairs {
println!("{:08b} {}", bits, digest);
fullhash.extend(cls);
fullhash = hash(&fullhash);
}
}
С другой стороны, цикл перевода замыкается на DexClass <'a>, что не так просто исправить. DexClass анализируется из входного файла dex, и он заимствовал ссылки в указанный файл. К сожалению, весь код синтаксического анализа dex и весь код, который использует проанализированные данные, предполагает, что он работает с заимствованными ссылками. Нет безопасного способа сделать его статичным, не внося серьезных изменений в код, чего я не хотел делать, тем более что это изначально излишняя пессимизация.
С тяжелым сердцем я обратился к самому опасному из небезопасных, mem::transmute, чтобы трансмутировать жизнь. В этом случае это должно быть безопасно, потому что все футуры ожидаются, пока заимствованные данные еще живы, но это очень легко испортить, и нет никакого способа узнать.
let mut results = Vec::new();
for data in dexes.iter() {
let dex = dex::DexFile::new(data);
let dex_classes = dex.parse_classes();
// futures_cpupool, y u no scoped threads?
let unsafe_classes: Vec<dex::DexClass<'static>> = unsafe{ mem::transmute(dex_classes) };
let result_futures: Vec<_> = unsafe_classes.into_iter().map(|cls| {
pool.spawn_fn(move || {
let unicode_name = mutf8::decode(cls.name).into_owned() + ".class";
let res = panic::catch_unwind(panic::AssertUnwindSafe(|| {
Ok(jvm::writeclass::to_class_file(&cls, opts))
})).unwrap_or_else(|err| {
let error_string = err.downcast::<String>().map(|b| *b).or_else(|err| {
err.downcast::<&'static str>().map(|s| s.to_string())
}).unwrap_or("panic with unknown type".to_string());
Err(error_string)
});
let res: Result<_,()> = Ok((unicode_name, res));
res
})
}).collect();
results.extend(result_futures.into_iter().map(|fut| fut.wait().unwrap()));
}
results
После всего этого код, наконец, скомпилирован ... и запущен ... и не дал никаких результатов.
Я до сих пор не уверен, в чем именно заключалась проблема, но после некоторой отладки я в конце концов догадался, что использование одного и того же пула потоков для обоих циклов каким-то образом вызывает тупик. Я изменил его, чтобы запускать каждый перевод в отдельном пуле потоков, и, наконец, это сработало.
Окончательные результаты
Обе версии передают результаты на консоль без снижения производительности. Версия Go немного «дёргается» - она делает паузу на некоторое время, затем сразу распечатывает кучу результатов, а затем снова делает паузу. Это не удивительно, поскольку результаты выполняются параллельно и хранятся в буфере, но это немного разочаровывает. Использование небуферизованного выходного канала уменьшило рывки, но не устранило их.
Версия на Rust только немного дёргается. Вам нужно будет очень внимательно присмотреться, чтобы отличить его от исходной последовательной версии, не считая того факта, что теперь он работает в 3,5 раза быстрее.
Я не думаю, что резкость доказывает, что Rust лучше - вероятно, это просто случайность, какой алгоритм планирования здесь лучше, но это была интересная разница.
Версия Rust также снизилась с 23,7 секунды до 23,1 секунды. Я не уверен, связано ли это с Rayon или CpuPool или это связано с распечаткой результатов параллельно с вычислениями.
Вывод
Распараллеливание неплохо ни на одном из языков. У каждого свои недостатки. В случае с Go это связано с отсутствием реальной системы типов. В случае с Rust это связано с тем, что библиотеки незрелые и не делают все, что вам нужно.
Как и раньше, мой опыт работы с Go показывает, что вы всегда знаете, какой у вас набор инструментов, но этот набор инструментов не очень велик, и вам нужно тратить время на размышления о том, какой способ создать то, что вы хотите, является наименее уродливым. С Rust вы тратите время на изучение библиотек и API, но полученный код лучше, чем его эквивалент в Go.
Кроме того, большая часть повторяющейся работы в Go тратится на изобретение велосипеда, что легко, но не нужно. Rust решает эту проблему с помощью вывода типов, обобщений, эргономичных встроенных функций и т.д. Rust также требует кучи повторяющейся работы, но, по крайней мере, для решения интересных задач - доказательства безопасности, исключения распределения и т.д. Go решает эту проблему даже не пытающийся.