 Dudochkin Victor
Dudochkin Victor
Влияние быстрых сетей на аналитику графов, часть 1
Перевод | Автор оригинала: Frank McSherry
tl;dr: В недавней статье NSDI утверждалось, что стеки аналитики данных не намного быстрее справляются с такими задачами, как PageRank, когда им предоставляется лучшая сеть, но это, скорее всего, просто свойство стека, которое они оценили (Spark и GraphX), а не в целом верно. Другая структура (своевременный поток данных) работает в 6 раз быстрее, чем GraphX в сети 1G, которая улучшается в 3–15-17 раз быстрее, чем GraphX в сети 10G.
Я провел последние несколько недель, посещая сотрудников CamSaS в компьютерной лаборатории Кембриджского университета. Вместе мы проделали интересную работу, о которой мы - Мальте Шварцкопф и я - собираемся вам рассказать.
Недавно на NSDI 2015 появилась статья, озаглавленная «Анализ производительности в инфраструктурах аналитики данных». Эта статья содержит некоторые удивительные результаты: в частности, в нем утверждается, что стеки аналитики данных в большей степени ограничены ЦП, чем сетевым или дисковым вводом-выводом. Конкретно,
«Оптимизация сети может сократить время выполнения задания в среднем не более чем на 2%. Сеть не является узким местом, потому что по сети передается гораздо меньше данных, чем на диск и с диска. В результате сетевой ввод-вывод практически не влияет на общую производительность даже в сетях со скоростью 1 Гбит / с ». (§1)
Измерения проводились с использованием Spark, но авторы утверждают, что они распространяются на другие системы. Мы подумали, что это было неожиданно, так как это не соответствует нашему опыту работы с другими системами обработки данных. В этом сообщении блога мы посмотрим, действительно ли эти наблюдения обобщают.
Одна из трех рабочих нагрузок в статье - это набор запросов BDBench от Беркли, который включает «вычисление, подобное ранжированию страницы». Более того, PageRank также появляется в качестве дополнительного примера в слайде NSDI (слайд 38–39), где он используется для иллюстрации того, что время выполнения задания может быть увеличено максимум на 10% даже при интенсивной работе в сети.
Это было особенно удивительно для нас из-за недавней дискуссии о том, нужны ли вообще для вычислений графов системы распределенной обработки данных. Несколько распределенных систем превосходит простую однопоточную реализацию на портативном компьютере для различных вычислений графов. Распространенная интерпретация состоит в том, что вычисления графов ограничены коммуникациями; сеть мешает, и вам будет лучше с одной машиной, если вычисления подходят.
Эти две позиции - (i) «PageRank не может быть улучшен более чем на 10% с помощью более быстрой сети» и (ii) «графические вычисления, такие как PageRank, связаны с коммуникацией и выигрывают от очень быстрой локальной коммуникации» - не делились друг с другом и подняли кучу вопросов: связаны ли эти вычисления с процессором или связью, или, возможно, это сложнее, чем это? И разве нельзя заставить несколько компьютеров, соединенных приличной сетью, работать быстрее, чем один компьютер?
Мы собираемся изучить производительность распределенного PageRank с использованием как GraphX (структура обработки графов поверх Spark), так и своевременного потока данных в кластере с сетевыми интерфейсами 1G и 10G.
-
Скорость сети может не иметь значения для стека на основе Spark, но имеет значение для высокопроизводительных аналитических стеков, особенно для обработки графов. При переходе от сети 1G к сети 10G мы видим увеличение производительности для своевременного потока данных в 2-3 раза.
-
Хорошо сбалансированная распределенная система предлагает улучшения производительности даже для задач обработки графов, которые подходят для одной машины; управление вещами на местном уровне не всегда лучшая стратегия.
-
Эффективность PageRank на GraphX в первую очередь зависит от системы. Мы видим увеличение производительности в 4–16 раз при использовании своевременного потока данных на одном и том же оборудовании, что говорит о том, что GraphX (и другие системы обработки графиков) оставляют тревожный уровень производительности на столе.
Очевидно, относитесь ко всем этим выводам с недоверием: мы обсудим некоторые оговорки и дизайнерские решения, с которыми некоторые могут не согласиться. Однако наш код доступен вместе с инструкциями, так что вы можете попробовать его сами!
Обзор
Мы решили понять узкие места в нетривиальном вычислении, которое мы хорошо понимаем: PageRank. Чтобы было ясно, PageRank - это не какое-то блестящее вычисление, но он более интересен, чем распределенный grep. Это хороший пример вычислений, которые обмениваются данными, объединяют данные и получают выгоду от сохранения индексированных данных, постоянно находящихся в памяти. Он также может быть реализован по-разному и, таким образом, помогает определить, насколько хорошо (или плохо) тот или иной подход соответствует конкретной системе.
Это также была хорошая возможность опробовать своевременный поток данных в Rust, который одновременно является портом для Rust и расширением парадигмы своевременного потока данных в Naiad. Своевременный поток данных в Rust пока запускался только на ноутбуке, так что это был хороший шанс избавиться от некоторых ошибок.
Кроме того, в Кембриджской компьютерной лаборатории есть новый «модельный центр обработки данных», который представляет собой современный кластер, оснащенный сетевым комплектом 10G, и мы хотели посмотреть, насколько быстро может работать этот код на Rust. Оказывается, теперь он довольно резво движется. Вот увидишь.
PageRank
PageRank - это не слишком сложное вычисление графа: идея состоит в том, что каждая вершина начинается с некоторого действительного «ранга», который она неоднократно делит по направленным ребрам со своими соседями. Если продолжать делать это достаточно долго, реальные рейтинги начинают стабилизироваться.
Вот простая последовательная реализация PageRank в Rust:
fn pagerank<G>(graph: &G: Graph, vertices: usize, alpha: f32)
{
// mutable per-vertex state
let mut src = vec![0f32; vertices];
let mut dst = vec![0f32; vertices];
let mut deg = vec![0f32; vertices];
// determine vertex degrees
for (x,_) in graph.edges() { deg[x] += 1f32; }
// perform 20 iterations
for _iteration in (0 .. 20) {
// prepare src ranks
for vertex in (0 .. vertices) {
src[vertex] = alpha * dst[vertex] / deg[vertex];
dst[vertex] = 1f32 - alpha;
}
// do the expensive part
for (x,y) in graph.edges() { dst[y] += src[x]; }
}
}
Если мы посмотрим на код, вычисление манипулирует состоянием каждой вершины (подготавливая src [vertex] и dst [vertex], используя deg [vertex]), а затем перемещается по графу, увеличивая dst [y] на src [x] для каждое ребро графа (x, y).
Единственная часть этого вычисления, которая затрудняет распараллеливание, - это обновление dst [y]: поскольку ребра могут связывать любые пары вершин, у нас нет априорного разделения ответственности за эти обновления. Так что нам придется это сделать.
Распределенный PageRank
Мы хотим сопоставить это вычисление между несколькими рабочими процессами (потоками, процессами или компьютерами), и, к счастью, есть несколько довольно простых способов сделать это. Наиболее распространенный подход - разделить ответственность за каждую вершину между рабочими, так что каждый рабочий отвечает примерно за равное количество вершин.1 Мы возложим ответственность за обработку вершины v на worker v% worker.
Чтобы разделить вычисление между рабочими, нам также необходимо разделить соответствующее состояние (входные и промежуточные данные). Входными данными для вычисления является просто набор ребер, поэтому мы должны убедиться, что ребро (x, y) доходит до worker x% worker.
После того, как мы распределили все ребра между рабочими, вычисление PageRank - это просто вопрос многократного применения обновлений для каждой вершины, которые каждый рабочий может выполнять независимо, а затем определения и передачи обновлений рангам других вершин.
Каждый рабочий подготавливает сообщение формы (y, src [x]), указывающее на предполагаемое обновление, вместо прямого применения + = к рангам. Эти обновления затем обмениваются между рабочими, то есть обновления вершины y отправляются рабочему y% worker.
Реализация №1: Отправить все
Это будет наша первая реализация, от которой мы быстро откажемся как до смешного неэффективности. Для каждого ребра (x, y) в вершине мы подготавливаем сообщение (y, rank), указывающее на заинтересованность в выполнении операции + = для конечного пункта y на границе. Мы обмениваемся всеми этими сообщениями, отправляя каждое рабочему, отвечающему за вершину получателя.
На рисунке ниже показано, как это будет происходить в настройке с четырьмя рабочими процессами (от w0 до w3) в двух процессах (P0 и P1).
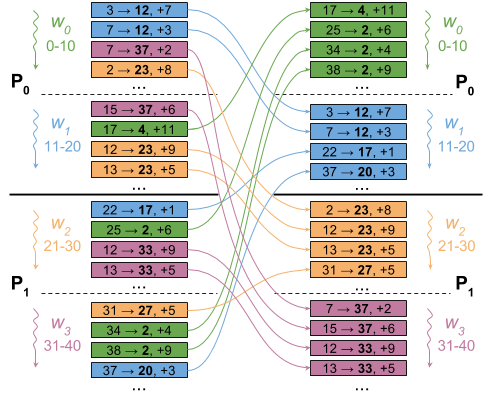
Однако этот подход должен отправлять некоторые данные по сети для каждого ребра в графе. Это, безусловно, приведет к серьезному общению, 2 и 10G будут выглядеть довольно хорошо по сравнению с 1G. Однако мы можем только сделать вывод, что довольно наивная реализация связана с коммуникацией. Посмотрим, сможем ли мы добиться большего.
Реализация # 2: агрегирование на уровне работника
Напомним, что каждый рабочий управляет несколькими вершинами. Их края вполне могут иметь общие пункты назначения, поэтому каждый работник может накапливать сообщения для каждого пункта назначения и отправлять только одно сообщение для каждого отдельного пункта назначения. Рабочий может накапливать эти обновления в хэш-таблице или в большом разреженном векторе (пропорциональном количеству вершин во всем графе), но есть гораздо более простой способ.
Каждый рабочий группирует свои ребра по назначению, а не по источнику. Поступая таким образом, работник может перебирать свои пункты назначения, накапливать свои обновления из каждого ранга источника, а затем выпускать одно обновление для пункта назначения.
Однопоточная интерпретация этого кода может выглядеть так:
// replaces "for (x, y) in graph.edges() { dst[y] += src[x]; }"
for (y, xs) in graph_transpose.edges() {
dst[y] += xs.map(|x| src[x]).sum();
}
Поскольку у каждого рабочего есть только ребра из вершин x, равных по модулю рабочих, каждое значение x / worker отличается. Мы можем сжать src на фактор рабочих, обращаясь к src [x / worker] вместо src [x]. По сравнению с подходом с группировкой источников, код выполняет произвольный доступ к небольшому вектору src, а не к большому вектору dst, что дает преимущество локальности.
Рисунок ниже иллюстрирует это: каждый воркер объединяет обновления для одного и того же места назначения (номер, выделенный жирным шрифтом) в одно обновление. В результате этот пример настройки с четырьмя рабочими заканчивается обменом только 12 сообщениями вместо 16 в простой версии.
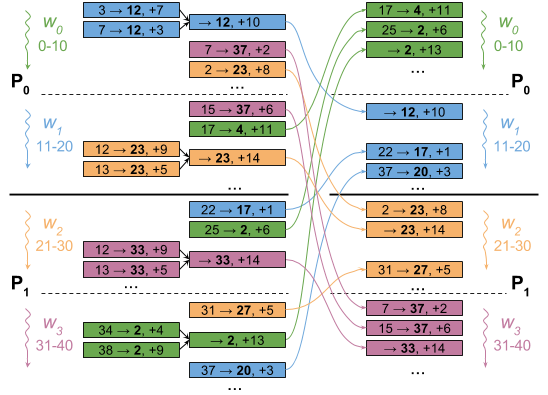
Более того, этот подход также производит выходные данные по мере продвижения, что позволяет работникам перекрывать общение с коммуникацией: работник может сразу же начать сообщать другим работникам о своих обновлениях, используя сеть одновременно с остальным компьютером.
Реализация # 3: агрегирование на уровне процесса
Реализация агрегации на уровне рабочих (# 2, выше) - наша наиболее эффективная реализация для сети 10G, но она по-прежнему отправляет довольно много данных.3 Чтобы более честно сравнить сети 1G и 10G, мы можем агрегировать немного более агрессивно. и переместите агрегирование на уровень процесса, чтобы еще больше уменьшить объем передаваемых данных. Однако это происходит за счет большего объема вычислений и большей синхронизации, поскольку агрегаты уровня процесса для нескольких рабочих процессов должны ожидать всех данных от каждого рабочего. Это уменьшает перекрытие вычислений и коммуникаций, которое мы можем делать, но в целом мы отправляем меньше данных.
Опять же, рисунок иллюстрирует это: после того, как мы агрегировали обновления на рабочем уровне, мы также агрегируем их на уровне процесса. В примере это уменьшает количество сообщений с 12 до 9.
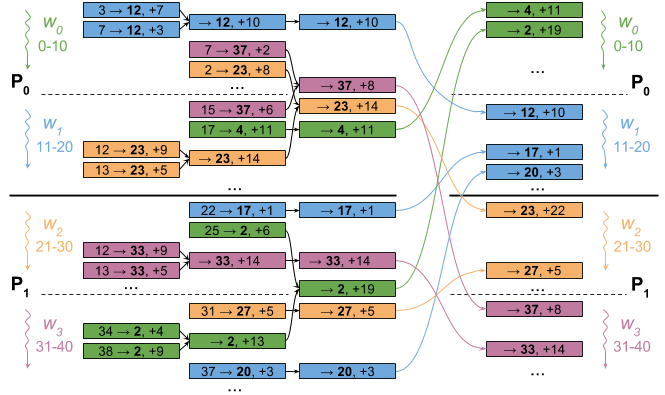
Мы могли бы потенциально попытаться сделать эту реализацию еще умнее, сократив вычисления и перекрыв коммуникацию. Однако, как мы покажем во второй части нашего исследования, мы не можем ожидать, что сеть 1G превзойдет 10G даже при бесконечно быстрой агрегации.
Оценка
Посмотрим, насколько хорошо работают наши реализации!
Мы оцениваем время, необходимое для выполнения двадцати итераций PageRank в кластере CamSaS 4, используя Spark / GraphX 1.4 и нашу своевременную реализацию потока данных.
Мы используем два графа, которые использовались в статье GraphX: реберный граф 1,4 млрд подписчиков в Twitter (twitter_rv) и граф ребер 3,7 млрд веб-ссылок (uk_2007_05). График uk_2007_05 также используется для результатов, показанных в слайде NSDI.
Некоторые базовые измерения
Прежде чем мы начнем, давайте подумаем о существующих базовых показателях, которые должны дать некоторый контекст.
Ниже мы показываем ранее опубликованные измерения Spark и GraphX, а также время выполнения GraphX в нашем кластере и время выполнения двух однопоточных реализаций (из статьи COST).
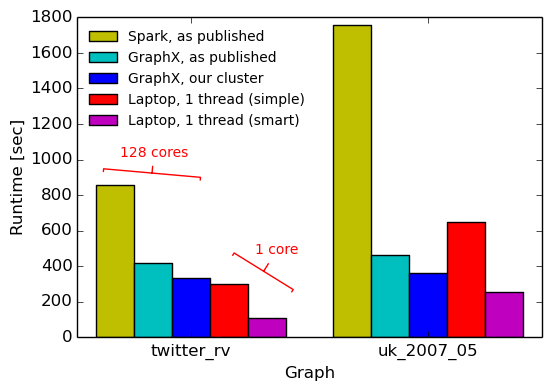
System source cores twitter_rv uk_2007_05 Spark GraphX paper 16x8 857s 1759s GraphX GraphX paper 16x8 419s 462s GraphX measured on our cluster 16x8 334s 362s Single thread (simpler) COST paper 1 300s 651s Single thread (smarter) COST paper 1 110s 256s Twenty pagerank iterations, baseline measurements.
Пока ничего нового: измерения на нашем кластере подтверждают, что числа из статьи GraphX могут быть воспроизведены, 5. Более того, ноутбук работает довольно хорошо, даже несмотря на то, что он использует только одно ядро ЦП, а не 128. На графике twitter_rv однопоточная реализация всегда превосходит распределенные реализации, а на графике uk_2007_05 простая однопоточная реализация всего лишь ~ 50% медленнее, чем GraphX (при сокращении ресурсов в 128 раз!). Более умная однопоточная реализация с графиком кривой заполнения гильбертова пространства всегда превосходит распределенные системы от 30% до 3x.
Это плохая новость для обработки распределенных графов в целом? Посмотрим.
Своевременная реализация потока данных
Давайте посмотрим на нашу реализацию параллельного обмена данными. Мы начнем с одной машины и перейдем от одного ядра к нескольким. Мы измеряем общее прошедшее время (первый график) и среднее время одной итерации последних десяти итераций (второй график). Для справки мы также показываем результаты для GraphX и простых однопоточных реализаций (в виде горизонтальных полос).
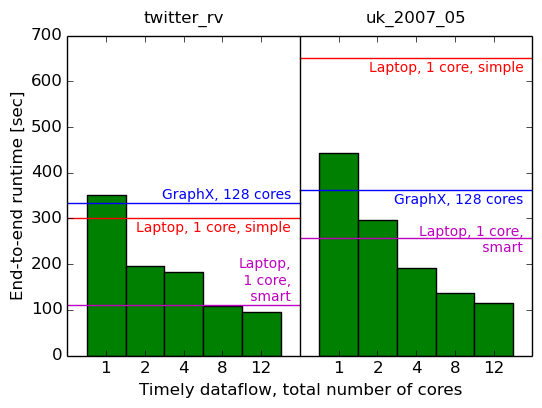
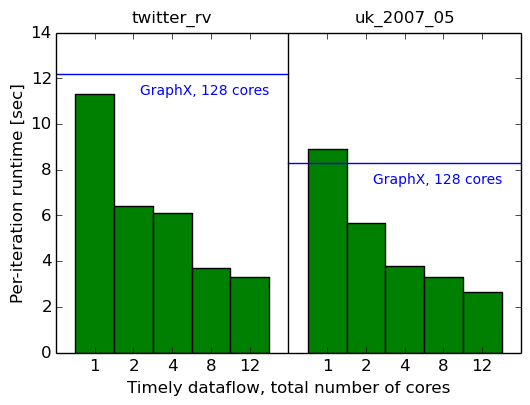
System cores twitter_rv uk_2007_05 Timely dataflow 1 350.7s (11.33s) 442.2s (8.90s) Timely dataflow 2 196.5s (6.39s) 297.3s (5.67s) Timely dataflow 4 182.4s (6.12s) 192.0s (3.78s) Timely dataflow 8 107.6s (3.70s) 137.1s (3.29s) Timely dataflow 12 95.0s (3.32s) 114.5s (2.65s)
Двадцать итераций рейтинга страниц на одной машине, несколько потоков.
Что ж, это хорошо: с одним потоком мы по-прежнему работаем так же, как GraphX на 128, и мы превосходим простое однопоточное измерение всего с двумя потоками6, и мы превосходим интеллектуальное однопоточное измерение с восемью потоками.7
Это говорит о том, что параллелизм внутри одной машины, по крайней мере, помогает ускорить эти вычисления. Может быть, несколько компьютеров со всей сетью между ними в конечном итоге станут медленнее?
Несколько компьютеров: 1G против 10G
Давайте теперь посмотрим, что происходит, когда мы распределяем вычисления по нескольким компьютерам. Здесь у нас есть выбор: использовать либо сетевой интерфейс 1G, либо сетевой интерфейс 10G; мы измерим оба значения, выявив прирост производительности, который дает 10G (если таковой имеется).
В дополнение к реализации агрегации на уровне рабочих, описанной выше, мы также включаем измерения для агрегации на уровне процессов в сети 1G (обозначенной «1G +»). Это больше соответствует реализации, оптимизированной для 1G, и соответствует тому, что делает GraphX.
Для каждой конфигурации мы снова указываем время, затраченное на выполнение двадцати итераций (первый график), и среднее значение последних десяти итераций (второй график). Поскольку GraphX и наша реализация имеют разные разовые начальные затраты, среднее время итерации при выполнении вычислений, вероятно, является наиболее справедливой метрикой для сравнения.
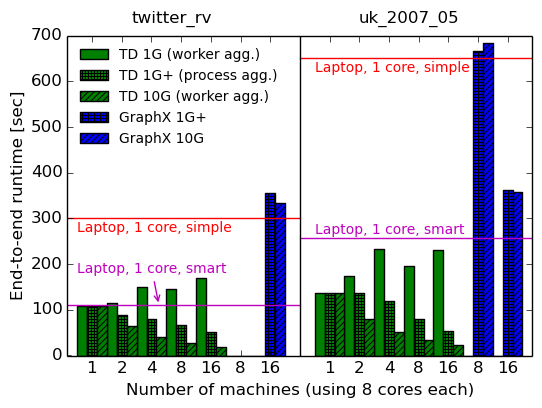
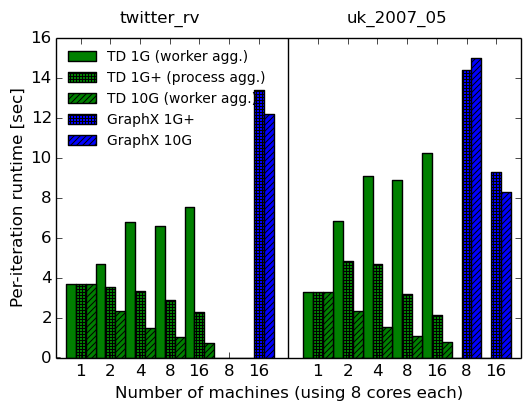
System cores 1G 1G+ 10G 10G speedup over 1G+ total per-iteration Timely dataflow 1x8 107.6s (3.70s) 107.6s (3.70s) 107.6s (3.70s) – – Timely dataflow 2x8 115.2s (4.66s) 89.0s (3.51s) 65.6s (2.34s) 1.36x 1.50x Timely dataflow 4x8 149.4s (6.77s) 80.9s (3.33s) 40.6s (1.49s) 1.99x 2.23x Timely dataflow 8x8 145.4s (6.60s) 66.5s (2.86s) 27.6s (1.05s) 2.41x 2.72x Timely dataflow 16x8 169.3s (7.51s) 51.8s (2.30s) 19.3s (0.75s) 2.68x 3.07x GraphX 16x8 354.8s (13.4s) 333.7s (12.2s) 1.06x 1.10x Elapsed and (per-iteration) times for twenty PageRank iterations on multiple machines using the twitter_rv graph, comparing 1G and 10G networks
System cores 1G 1G+ 10G 10G speedup over 1G+ total per-iteration Timely dataflow 1x8 137.1s (3.29s) 137.1s (3.29s) 137.1s (3.29s) – – Timely dataflow 2x8 173.3s (6.82s) 135.8s (4.82s) 80.7s (2.31s) 1.68x 2.09x Timely dataflow 4x8 231.9s (9.06s) 119.1s (4.67s) 51.4s (1.54s) 2.32x 3.03x Timely dataflow 8x8 196.4s (8.87s) 80.1s (3.18s) 34.1s (1.07s) 2.35x 2.97x Timely dataflow 16x8 231.2 (10.25s) 53.9s (2.13s) 23.7s (0.76s) 2.27x 2.80x GraphX 8x8 666.8s (14.40s) 682.6s (15.00s) 0.98x 0.96x GraphX 16x8 361.8s (9.30s) 357.9s (8.30s) 1.01x 1.12x
Истекшее время и время (на итерацию) для двадцати итераций PageRank на нескольких машинах с использованием графика uk_2007_05 для сравнения сетей 1G и 10G
Уф, это много данных! Однако есть несколько важных наблюдений, которые мы можем извлечь из них:
-
Ускорение сети не сильно улучшает производительность GraphX (максимум на 10–12%), что подтверждает наблюдения статьи NSDI.
-
Ускорение сети действительно улучшает производительность своевременного потока данных (в 2-3 раза), что ограничивает универсальность выводов, сделанных в документе NSDI.
-
Стоимость связи не влияет на производительность GraphX, но она действительно влияет на производительность своевременного потока данных, а это означает, что вычисления графов могут быть связаны с обменом данными при хорошей реализации.
-
Тем не менее, производительность строго улучшается по мере того, как мы добавляем машины, что делает недействительным утверждение о том, что распределенные системы не будут быстрее, чем одна машина, при выполнении вычисления графа с привязкой к обмену данными на графе, который вписывается в машину.
-
Агрегация на уровне рабочих оказывает противоположное влияние на сеть 10G и сеть 1G: на 10G она дает улучшения, но на 1G она замедляет работу. Более того, в 10G агрегирование на уровне рабочих превосходит агрегирование на уровне процессов (не показано на графиках), несмотря на отправку большего количества данных.
-
GraphX хорошо масштабируется от восьми до шестнадцати машин на графике uk_2007_05, но, как предполагается в статье COST, такая масштабируемость могла быть вызвана просто распараллеливанием накладных расходов.
-
Своевременный поток данных в сети 10G превосходит GraphX до 16 раз по времени выполнения за итерацию с использованием 16 машин (16,27x для twitter_rv и 10,92x для uk_2007_05).
Эти результаты позволяют нам ответить на наши вопросы с самого начала, как мы сейчас увидим.
Заключение (на данный момент)
На этом первая часть нашего расследования завершена. Очевидно, и сети 10G, и системы распределенной обработки данных полезны для PageRank. Уф. Экзистенциальный кризис предотвращен!
Как мы видели, три реализации (GraphX и две реализации своевременного потока данных) имеют разные узкие места. GraphX выполняет больше вычислений и привязан к ЦП даже в сети 1G, тогда как более компактные реализации своевременного потока данных становятся привязанными к ЦП только в сети 10G. Выводы о масштабируемости или ограничениях одной системы на основе производительности другой, вероятно, ошибочны.
Быстрые сети 10G действительно помогают сократить время выполнения параллельных вычислений более чем на 2-10%: мы наблюдали увеличение скорости до 3 раз при переходе с 1G на 10G. Однако структура вычислений и реализация системы обработки данных должны подходить для быстрых сетей, а для сетей 1G и 10G подходят разные стратегии. Последним иногда действительно помогает быть менее умным и больше общаться.
Распределенная обработка данных имеет смысл даже для вычислений графов, когда граф умещается на одной машине. Когда вычисления и обмен данными в достаточной степени перекрываются, использование нескольких машин дает ускорение до 5 раз (например, на twitter_rv, 1x8 против 16x8). Запускать все локально не обязательно быстрее.
Более того, мы показали, что с помощью распределенного своевременного потока данных можно повысить скорость PageRank в 16 раз на итерацию, чем с помощью GraphX (с 12,2 до 0,75 с на итерацию). Это говорит нам кое-что о том, сколько возможностей для улучшения есть даже по сравнению с цифрами, которые в настоящее время считаются самыми современными в исследованиях!
Во второй части мы продолжим более глубокий анализ того, почему своевременный поток данных намного быстрее, чем GraphX. Мы рассмотрим их соответствующее использование ресурсов во время выполнения вычислений и исследуем с помощью анализа нижней границы, возможно ли вообще сделать сеть 1G лучше, чем сеть 10G, путем хитрого агрегирования (спойлер: это не так!).
Вернитесь, чтобы получить больше через несколько дней!
-
Это мнение распространено даже у тех, кто создает системы обработки распределенных графов: несколько месяцев назад Рейнольд Ксин (соавтор GraphX, теперь в Databricks) указал, что для рабочих нагрузок графов с привязкой к обмену данными, которые подходят для машины, существует нет смысла распространяться. Это несколько удивительная позиция: конечно, можно ожидать, что распределенная система обработки графов (такая как GraphX) и приличная сеть превзойдут ноутбук по проблемам с графами? Возможно, Рейнольд говорит, что «такие системы, как GraphX, разработаны для графов, которые слишком велики, чтобы поместиться на одной машине; нет никакой пользы от использования их на тех, которые подходят к машине ». Это разумная точка зрения, хотя тот факт, что все известные результаты GraphX представлены на таких графиках, предполагает, что системы необходимо оценивать с использованием более крупных графиков. В любом случае позже мы покажем, что распределенная система действительно превосходит одиночную машину даже для графиков, которые вписываются в машину.
-
Некоторые системы обработки графов (например, PowerGraph) используют гораздо более сложные и хитрые схемы, чтобы сбалансировать объем работы, которую должен выполнять каждый рабочий. Как мы увидим, на практике это не кажется необходимым.
-
Если мы представим конечный пункт назначения 32-битным целым числом, а значение обновления - числом с плавающей запятой одинарной точности, мы закончим тем, что каждая машина будет отправлять и получать ~ 15 ГБ сообщений на итерацию при обработке широко используемого twitter_rv график. Явно не лучший план.
-
Около 3 ГБ на итерацию для каждой машины на графе twitter_rv.
-
Кластер CamSaS состоит из 16 машин, каждая из которых оснащена процессором Intel Xeon E5-2430Lv2 (12 гиперпотоков, 2,4 ГГц), 64 ГБ оперативной памяти DDR3-1600, твердотельным накопителем Micron P400m-MTF для корневой файловой системы и Toshiba MG03ACA1. Жесткий диск 7200 об / мин для данных, а также встроенная сетевая карта 1G и Intel X520 10G. Мы запускаем Ubuntu 14.04 (надежное) ядро Linux 3.13.0-24 по умолчанию, а жесткий диск разбит на разделы с использованием файловой системы ext4. Мы используем стандартный дистрибутив Spark 1.4, в который входит GraphX.
-
Мы подозреваем, что наши результаты немного лучше, чем в статье о GraphX, потому что мы используем выделенные машины (в отличие от экземпляров m2.4xlarge EC2).
-
Вы можете задаться вопросом, почему это однопоточное измерение медленнее, чем простое однопоточное измерение, описанное ранее: это потому, что структурирование программы как потока данных добавляет некоторые накладные расходы.
-
Более умная однопоточная реализация использует «экзотический» макет графа (основанный на кривой заполнения гильбертова пространства); хотя этот метод можно применить для своевременного потока данных, в этой публикации мы не будем использовать его в распределенной реализации.