 Dudochkin Victor
Dudochkin Victor
Знакомство с быстрым, безопасным и полным веб-сервисом в Rust
Перевод | Автор оригинала: Brandur
Уже много лет у меня кризис веры в переводимые языки. С ними быстро и весело работать в небольших масштабах, но когда у вас есть крупный проект, их привлекательный внешний вид быстро смывается. Большая программа на Ruby или JavaScript (и это лишь некоторые из них) в производстве - это бесконечная игра в шутку: вы решаете одну проблему только для того, чтобы найти новую где-то еще. Независимо от того, сколько тестов вы напишете или насколько хорошо дисциплинирована ваша команда, любая новая разработка обязательно приведет к потоку ошибок, которые необходимо будет исправлять в течение месяцев или лет.
Центральное место в проблеме занимают края. Люди будут надежно проделывать хорошую работу по построению и тестированию счастливых путей, но мы, люди, ужасно не умеем учитывать крайние условия, и именно эти грани и углы вызывают проблемы на протяжении многих лет, в течение которых программа работает.
Такие ограничения, как компилятор и система распознавания типов, - это инструменты, которые помогают нам находить эти грани и думать о них. В мире языков программирования существует широкий спектр вседозволенности, и прямо сейчас мой тезис состоит в том, что больше времени, потраченного на разработку, удовлетворяющую правилам языка, приведет к тому, что меньше времени будет тратиться на устранение проблем в Интернете.
Rust
Если можно построить более надежные системы с помощью языков программирования с более строгими ограничениями, как насчет языков с наиболее строгими ограничениями? Я полностью перешагнул границы диапазона и создал веб-сервис на Rust, языке, печально известном своим бескомпромиссным компилятором.
Язык все еще новый и несколько непрактичный. Изучение правил, касающихся типов, владения и продолжительности жизни, было утомительным занятием. Несмотря на трудности, это был интересный опыт обучения, и он работает. Я сталкиваюсь с меньшим количеством забытых граничных условий, и ошибок времени выполнения становится меньше. Широкий рефакторинг больше не вызывает ужаса.
Здесь мы рассмотрим некоторые из наиболее новых идей и возможностей Rust, его основных библиотек и различных фреймворков, которые делают это возможным.
Основа
Я построил свой сервис на actix-web, веб-фреймворке, основанном на actix, библиотеке акторов для Rust. actix похож на то, что вы можете увидеть в таком языке, как Erlang, за исключением того, что он добавляет еще одну степень надежности и скорости за счет интенсивного использования сложных систем типов и параллелизма Rust. Например, для актора невозможно получить сообщение, которое он не может обработать во время выполнения, потому что оно было бы запрещено во время компиляции.
Есть небольшая вероятность, что вы узнаете это имя, потому что actix-web пробился на вершину тестов TechEmpower. Программы, созданные для такого рода тестов, часто оказываются немного надуманными из-за их оптимизации, но это теперь надуманный код Rust, который занимает первое место в списке с надуманным кодом C++ и Java. Но независимо от того, как вы относитесь к достоверности программ тестирования, вывод состоит в том, что actix-web работает быстро.
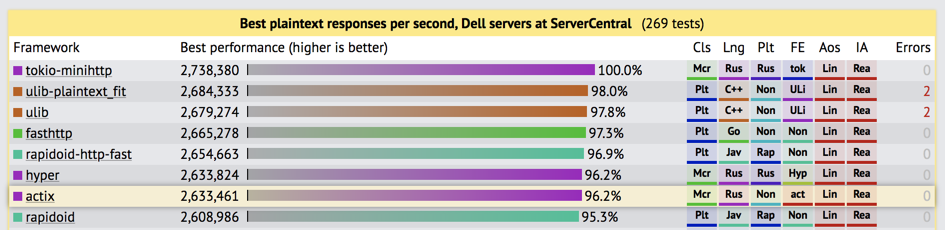
Rust неизменно занимает место в рейтинге TechEmpower наряду с C++ и Java.
Автор actix-web (и actix) фиксирует колоссальный объем кода - проекту всего около шести месяцев, и он не только уже более полнофункциональный и с лучшими API-интерфейсами, чем веб-фреймворки на других языках с открытым исходным кодом, но и больше, чем многие фреймворки, финансируемые крупными организациями с огромными командами разработчиков. Такие тонкости, как HTTP / 2, WebSockets, быстрые ответы, плавное завершение работы, HTTPS, поддержка файлов cookie, обслуживание статических файлов и хорошая инфраструктура тестирования доступны прямо из коробки. Документация все еще немного грубовата, но я еще не обнаружил ни одной ошибки.
Проверка дизельного топлива и запросов во время компиляции
Я использовал дизельное топливо в качестве ORM, чтобы поговорить с Postgres. Самым приятным в этом проекте является то, что это ORM, написанный кем-то с большим прошлым опытом создания ORM, потратившим много времени в окопах с Active Record. Многие из ловушек, характерных для ORM предыдущих поколений, удалось избежать - например, дизель не пытается делать вид, что диалекты SQL во всех основных базах данных одинаковы, он исключает настраиваемый DSL для миграции (вместо этого используется необработанный SQL), и он не выполняет автоматическое управление подключением на глобальном уровне. Он действительно встраивает мощные функции Postgres, такие как upsert и jsonb, прямо в основную библиотеку и по возможности обеспечивает мощные механизмы безопасности.
Большинство моих запросов к базе данных написаны с использованием типобезопасного DSL дизельного двигателя. Если я неправильно ссылаюсь на поле, пытаюсь вставить кортеж в неправильную таблицу или даже создаю невозможное соединение, компилятор сообщает мне об этом. Вот типичная операция (в данном случае пакет Postgres INSERT INTO ... ON CONFLICT ... или "upsert"):
time_helpers::log_timed(&log.new(o!("step" => "upsert_episodes")), |_log| {
Ok(diesel::insert_into(schema::episode::table)
.values(ins_episodes)
.on_conflict((schema::episode::podcast_id, schema::episode::guid))
.do_update()
.set((
schema::episode::description.eq(excluded(schema::episode::description)),
schema::episode::explicit.eq(excluded(schema::episode::explicit)),
schema::episode::link_url.eq(excluded(schema::episode::link_url)),
schema::episode::media_type.eq(excluded(schema::episode::media_type)),
schema::episode::media_url.eq(excluded(schema::episode::media_url)),
schema::episode::podcast_id.eq(excluded(schema::episode::podcast_id)),
schema::episode::published_at.eq(excluded(schema::episode::published_at)),
schema::episode::title.eq(excluded(schema::episode::title)),
))
.get_results(self.conn)
.chain_err(|| "Error upserting podcast episodes")?)
})
Более сложный SQL сложно представить с помощью DSL, но, к счастью, есть отличная альтернатива в виде встроенного в Rust include_str! макрос. Он принимает содержимое файла во время компиляции, и мы можем легко передать его дизелю для привязки параметров и выполнения:
diesel::sql_query(include_str!("../sql/cleaner_directory_search.sql"))
.bind::<Text, _>(DIRECTORY_SEARCH_DELETE_HORIZON)
.bind::<BigInt, _>(DELETE_LIMIT)
.get_result::<DeleteResults>(conn)
.chain_err(|| "Error deleting directory search content batch")
Запрос находится в собственном файле .sql:
WITH expired AS (
SELECT id
FROM directory_search
WHERE retrieved_at < NOW() - $1::interval
LIMIT $2
),
deleted_batch AS (
DELETE FROM directory_search
WHERE id IN (
SELECT id
FROM expired
)
RETURNING id
)
SELECT COUNT(*)
FROM deleted_batch;
При таком подходе мы теряем проверку SQL во время компиляции, но получаем прямой доступ к чистой силе семантики SQL и отличной подсветке синтаксиса в вашем любимом редакторе.
Быстрая (но не самая быстрая) модель параллелизма
actix-web работает на базе tokio, библиотеки быстрого цикла событий, которая является краеугольным камнем истории параллелизма 1. При запуске HTTP-сервера actix-web порождает количество рабочих процессов, равное количеству логических ядер на сервере, каждое в своем собственный поток, и у каждого свой токио-реактор.
Обработчики HTTP могут быть написаны разными способами. Мы могли бы написать такой, который возвращает контент синхронно:
fn index(req: HttpRequest) -> Bytes {
...
}
Это заблокирует базовый реактор tokio до его завершения, что уместно в ситуациях, когда не требуется выполнять другие вызовы блокировки; например, рендеринг статического представления из памяти или ответ на проверку работоспособности.
Мы также можем написать обработчик HTTP, который возвращает упакованное будущее. Это позволяет нам объединить в цепочку серию асинхронных вызовов, чтобы гарантировать, что реактор никогда не будет без необходимости заблокирован.
fn index(req: HttpRequest) -> Box<Future<Item=HttpResponse, Error=Error>> {
...
}
Примерами этого могут быть ответ файла, который мы читаем с диска (блокировка ввода-вывода, хотя и минимальная), или ожидание ответа от нашей базы данных. Ожидая результатов в будущем, базовый реактор tokio с радостью выполнит другие запросы.

Пример модели параллелизма с actix-web.
Синхронные актеры
Поддержка футур в Rust широко распространена, но не универсальна. Примечательно, что дизель не поддерживает асинхронные операции, поэтому все его операции будут блокироваться. Использование его непосредственно в HTTP-обработчике actix-web заблокировало бы tokio-реактор потока и не позволило бы этому исполнителю обслуживать другие запросы до завершения операции.
К счастью, у actix есть отличное решение этой проблемы в виде синхронных актеров. Это субъекты, которые рассчитывают выполнять свои рабочие нагрузки синхронно, поэтому каждому назначается собственный выделенный поток на уровне ОС. Абстракция SyncArbiter предназначена для простого запуска нескольких копий одного типа акторов, каждая из которых совместно использует очередь сообщений, чтобы можно было легко отправить работу набору (указан как адрес ниже):
// Start 3 `DbExecutor` actors, each with its own database
// connection, and each in its own thread
let addr = SyncArbiter::start(3, || {
DbExecutor(SqliteConnection::establish("test.db").unwrap())
});
Хотя операции внутри синхронного актора блокируются, другим субъектам в системе, таким как HTTP-воркеры, не нужно ждать завершения какого-либо из них - они получают назад будущее, которое представляет результат сообщения, чтобы они могли выполнять другую работу.
В моей реализации быстрые рабочие нагрузки, такие как парсинг параметров и визуализация представлений, выполняются внутри обработчиков, а синхронные акторы никогда не вызываются, если в этом нет необходимости. Когда ответ требует операций с базой данных, сообщение отправляется синхронному субъекту, а базовый токио-реактор HTTP-исполнителя обслуживает другой трафик, ожидая разрешения будущего. Когда это происходит, он отображает HTTP-ответ с результатом и отправляет его обратно ожидающему клиенту.
Управление подключением
На первый взгляд, введение синхронных акторов в систему может показаться чисто недостатком, поскольку они являются верхней границей параллелизма. Однако этот предел также может быть преимуществом. Одна из первых проблем масштабирования, с которой вы, вероятно, столкнетесь с Postgres, - это его скромные ограничения на максимальное количество разрешенных одновременных подключений. Даже самые большие экземпляры на Heroku или GCP (Google Cloud Platform) имеют максимум 500 подключений, а меньшие экземпляры имеют ограничения, которые намного ниже (моя небольшая база данных GCP ограничивает меня до 25). Большие приложения с грубыми схемами управления соединениями (например, Rails, а также многие другие), как правило, прибегают к таким решениям, как PgBouncer, чтобы обойти проблему.
Указание количества синхронных участников по расширению также подразумевает максимальное количество подключений, которые служба будет использовать, что приводит к идеальному контролю над ее использованием.

Соединения поддерживаются только тогда, когда он нужен синхронному актору.
Я написал свои синхронные акторы, чтобы проверять отдельные соединения из пула соединений (r2d2) только при начале работы и возвращать их обратно после того, как они будут выполнены. Когда служба простаивает, запускается или завершается, она не использует никаких подключений. Сравните это со многими веб-фреймворками, где принято открывать соединение с базой данных при запуске рабочего и сохранять его открытым, пока рабочий рабочий. Этот подход требует ~ 2x соединения для плавного перезапуска, потому что все поэтапно подключенные рабочие немедленно устанавливают соединение, даже если все поэтапно отключенные рабочие все еще держатся за одно.
Эргономическое преимущество синхронного кода
Синхронные операции не так быстры, как чисто асинхронный подход, но их преимущество заключается в простоте использования. Приятно, что футуры бывают быстрыми, но их правильная компоновка требует времени, а ошибки компилятора, которые они генерируют, если вы допустили ошибку, действительно являются кошмаром, что приводит к тому, что на отладку уходит много времени.
Написание синхронного кода происходит быстрее и проще, и меня лично устраивает несколько неоптимальная скорость выполнения, если это означает, что я могу быстрее реализовать больше основной логики предметной области.
Медленно, но только относительно "очень, ОЧЕНЬ быстро"
Это может показаться пренебрежительным по отношению к характеристикам производительности этой модели, но имейте в виду, что она медленная по сравнению с чисто асинхронным стеком (то есть футурами повсюду). Это все еще концептуально продуманная модель параллелизма с реальным параллелизмом, и по сравнению почти с любыми другими фреймворками и языками программирования, она по-прежнему очень-очень быстрая. Я пишу Ruby в своей повседневной работе, и по сравнению с нашей беспоточной моделью (нормальной для Ruby, потому что GIL ограничивает производительность потоков) с использованием процессов разветвления на виртуальной машине без уплотняющего сборщика мусора, мы говорим о более высокой скорости и эффективности памяти на несколько порядков. , без труда.
В конце концов, ваша база данных будет узким местом для параллелизма, а модель синхронных акторов поддерживает примерно столько параллелизма, сколько мы можем ожидать от нее, а также поддерживает максимальную пропускную способность для любых действий, которые не требуются. доступ к базе данных.
Обработка ошибок
Как и любая хорошая программа на Rust, API почти повсюду возвращают тип Result. Футуры проходят через свою собственную версию Result, содержащую либо успешный результат, либо ошибку.
Я использую цепочку ошибок, чтобы определять свои ошибки. Большинство из них являются внутренними, но я определил определенную группу с явной целью взаимодействия с пользователем:
error_chain!{
errors {
//
// User errors
//
BadRequest(message: String) {
description("Bad request"),
display("Bad request: {}", message),
}
}
}
Когда пользователю необходимо сообщить об ошибке, я обязательно сопоставил ее с одним из типов ошибок пользователя:
Params::build(log, &request).map_err(|e|
ErrorKind::BadRequest(e.to_string()).into()
)
После ожидания синхронного актора и попытки создать успешный HTTP-ответ я потенциально обрабатываю пользовательскую ошибку и визуализирую ее. Реализация оказывается довольно элегантной (обратите внимание, что в будущем композиция будет отличаться от and_then тем, что она обрабатывает успех или неудачу, получая Результат, в отличие от and_then, которое только цепляется за успех):
let message = server::Message::new(&log, params);
// Send message to synchronous actor
sync_addr
.send(message)
.and_then(move |actor_response| {
// Transform actor response to HTTP response
}
.then(|res: Result<HttpResponse>|
server::transform_user_error(res, render_user_error)
)
.responder()
Ошибки, не предназначенные для того, чтобы пользователь мог их увидеть, регистрируются, и actix-web отображает их как внутреннюю ошибку сервера 500 (хотя в какой-то момент я, скорее всего, добавлю для них пользовательский рендерер).
Вот transform_user_error. Функция рендеринга является абстракцией, поэтому мы можем повторно использовать ее в общем случае между API, который отображает ответы JSON, и веб-сервером, который отображает HTML.
pub fn transform_user_error<F>(res: Result<HttpResponse>, render: F) -> Result<HttpResponse>
where
F: FnOnce(StatusCode, String) -> Result<HttpResponse>,
{
match res {
Err(e @ Error(ErrorKind::BadRequest(_), _)) => {
// `format!` activates the `Display` traits and shows our error's `display`
// definition
render(StatusCode::BAD_REQUEST, format!("{}", e))
}
r => r,
}
}
ПО промежуточного слоя
Как и веб-фреймворки на многих языках, actix-web поддерживает промежуточное ПО. Вот простой пример, который инициализирует регистратор для каждого запроса и устанавливает его в расширения запроса (набор состояний запроса, который будет существовать, пока существует запрос):
pub mod log_initializer {
pub struct Middleware;
pub struct Extension(pub Logger);
impl<S: server::State> actix_web::middleware::Middleware<S> for Middleware {
fn start(&self, req: &mut HttpRequest<S>) -> actix_web::Result<Started> {
let log = req.state().log().clone();
req.extensions().insert(Extension(log));
Ok(Started::Done)
}
fn response(
&self,
_req: &mut HttpRequest<S>,
resp: HttpResponse,
) -> actix_web::Result<Response> {
Ok(Response::Done(resp))
}
}
/// Shorthand for getting a usable `Logger` out of a request.
pub fn log<S: server::State>(req: &mut HttpRequest<S>) -> Logger {
req.extensions().get::<Extension>().unwrap().0.clone()
}
}
Приятной особенностью является то, что состояние промежуточного программного обеспечения привязано к типу, а не к строке (как, например, вы можете найти с Rack в Ruby). Это не только дает преимущество проверки типов во время компиляции, так что вы не можете ошибиться при вводе ключа, но также дает промежуточному программному обеспечению возможность контролировать свою модульность. Если бы мы хотели строго инкапсулировать промежуточное ПО, описанное выше, мы могли бы удалить pub из расширения, чтобы оно стало закрытым. Любые другие модули, которые попытались получить доступ к его регистратору, не смогли бы сделать это с помощью проверок видимости в компиляторе.
Асинхронность на всем пути вниз
Как и обработчики, промежуточное ПО actix-web может быть асинхронным, возвращая future вместо Result. Это, например, позволит нам реализовать промежуточное ПО с ограничением скорости, которое обращается к Redis таким образом, чтобы не блокировать HTTP worker. Я уже упоминал, что actix-web работает довольно быстро?
HTTP-тестирование
actix-web содержит несколько рекомендаций по методикам тестирования HTTP. Я остановился на серии модульных тестов, которые используют TestServerBuilder для создания минимального приложения, содержащего единственный целевой обработчик, а затем выполняют запрос против него. Это хороший компромисс, потому что, несмотря на то, что тесты минимальны, они, тем не менее, используют сквозной фрагмент HTTP-стека, что делает их быстрыми и полными:
#[test]
fn test_handler_graphql_get() {
let bootstrap = TestBootstrap::new();
let mut server = bootstrap.server_builder.start(|app| {
app.middleware(middleware::log_initializer::Middleware)
.handler(handler_graphql_get)
});
let req = server
.client(
Method::GET,
format!("/?query={}", test_helpers::url_encode(b"{podcast{id}}")).as_str(),
)
.finish()
.unwrap();
let resp = server.execute(req.send()).unwrap();
assert_eq!(StatusCode::OK, resp.status());
let value = test_helpers::read_body_json(resp);
// The `json!` macro is really cool:
assert_eq!(json!({"data": {"podcast": []}}), value);
}
Я активно использую serde_json (стандартная библиотека кодирования и декодирования Rust JSON) json! макрос, используемый в последней строке приведенного выше кода. Если вы присмотритесь, то заметите, что встроенный JSON не является строкой - json! позволяет мне записывать фактическую нотацию JSON прямо в мой код, который проверяется и преобразуется компилятором в допустимую структуру Rust. Это, безусловно, самый элегантный подход к тестированию ответов HTTP JSON, который я когда-либо видел на любом языке программирования.
Резюме: является ли Rust будущим отказоустойчивости?
Было бы справедливо сказать, что я мог бы написать эквивалентный сервис на Ruby за десятую часть времени, которое мне потребовалось, чтобы написать этот на Rust. Отчасти это требует обучения Rust, но многое - нет - язык краток для написания, но успокоение компилятора часто бывает долгим и утомительным процессом.
Тем не менее, я снова и снова сталкивался с тем, что преодолевал это последнее препятствие, запускал свою программу и испытывал эйфорию в стиле Хаскеля, когда видел, как она работает именно так, как я предполагал. Сравните это с интерпретируемым языком, на котором вы запускаете его с 15-й попытки, и даже тогда граничные условия почти наверняка все еще неверны. Rust также делает возможными большие изменения - для меня нет ничего необычного в рефакторинге тысячи строк за раз и, опять же, после этого программа отлично работает. Любой, кто видел большую программу на интерпретируемом языке в производственном масштабе, знает, что вы никогда не развернете масштабный рефакторинг для важной службы, кроме как небольшими фрагментами - все остальное слишком рискованно.
Стоит ли писать свой следующий веб-сервис на Rust? Я еще не знаю, но сейчас мы подходим к тому моменту, когда вы должны хотя бы рассмотреть это.