 Dudochkin Victor
Dudochkin Victor
lolbench: автоматическое и эмпирическое обнаружение регрессии производительности Rust
Перевод | Автор оригинала: Adam Perry
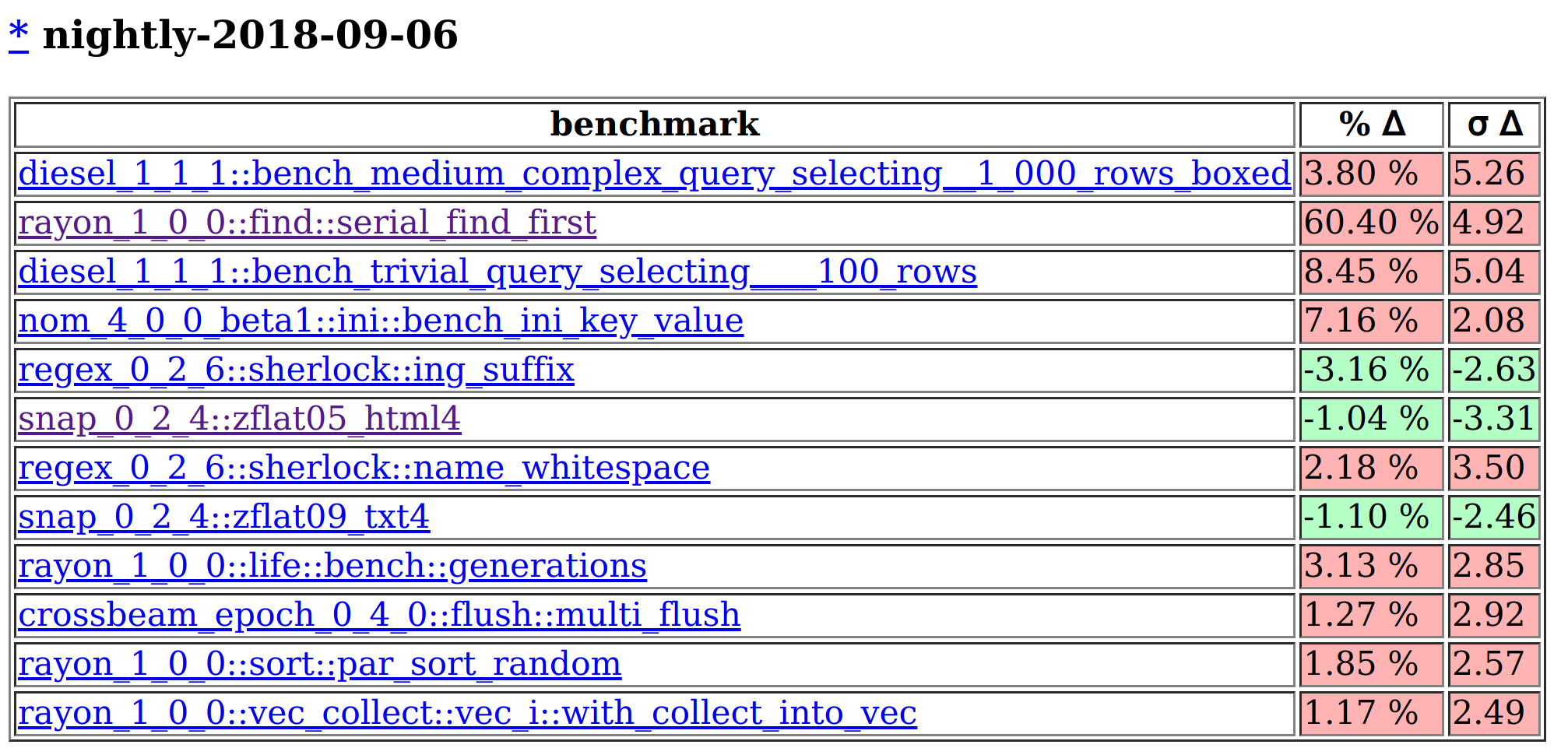
lolbench компилирует ~ 350 тестов с каждым Rust каждую ночь. Затем он запускает их и выделяет потенциальные падения производительности в стандартной библиотеке и на выходе компилятора. Запуск каждой цепочки инструментов резюмируется со списком вероятных кандидатов, как показано на изображении ниже, и теперь мы начинаем использовать их для защиты производительности программ Rust. Приходите на помощь!
Я работал над тем, что вы могли бы назвать набором регрессионных тестов производительности для сгенерированных двоичных файлов Rust, состоящих из «живых» тестов Rust, которые инструментированы, построены с множеством разных версий компилятора и запускаются при измерении в нескольких Габаритные размеры. Набор тестов также включает инструменты для определения аномальных или интересных прогонов тестов.
И, к моему крайнему удивлению, ЭТО ТАКОЕ, КАК ЭТО РАБОТАЕТ. Он называется «lolbench», потому что мне нужен был заполнитель, но теперь я работал над ним слишком долго, не придумав лучшего, так что это название. Вы можете посетить веб-сайт, где подведены итоги, если хотите взглянуть на это.
Если у вас нет времени читать это, но проект кажется вам интересным, приходите на помощь! Несколько способов:
- Помогите сократить этот список тестов, в переносе которых мы хотели бы помочь. В README есть инструкции по добавлению новых тестов.
- У вас есть код, который был замедлен из-за предыдущей версии Rust? Знаете ли вы, что исследования в области программной инженерии показывают, что после того, как вы увидели ошибку пару раз, вероятность увидеть ее снова возрастает? Отправьте PR, чтобы этого не произошло!
- Есть масса способов улучшить инфраструктуру бегуна, качество анализа и веб-сайт отчетности. Существует множество проблем, связанных с документированием некоторых из них в репозитории GitHub.
Я писал о своем прогрессе на канале # wg-codegen на irc.mozilla.org как anp, и я более чем счастлив поболтать там!
Выявление потенциальных регрессий
Если мы зайдем на сайт, созданный lolbench, и прокрутим список потенциально аномальных результатов до начала сентября 2018 года, мы увидим что-то вроде этого:

Это говорит нам о том, что тест rayon_1_0_0::find::serial_find_first имел время выполнения с использованием инструментальной цепочки 2018-09-06, которое было на 60% дольше, чем среднее время выполнения для всех инструментальных цепочек, которые мы записали до этого. Это представляет собой изменение почти на 5 стандартных отклонений от среднего значения, так что оно довольно значительное, и его определенно стоит проверить!
Давайте кликнем по названию теста, хотя из моего ленивого снимка экрана вы можете заметить, что я уже это сделал. Нас встречает что-то вроде этого, хотя и без очень полезного прямоугольника, который говорит нам, где искать (TODO):
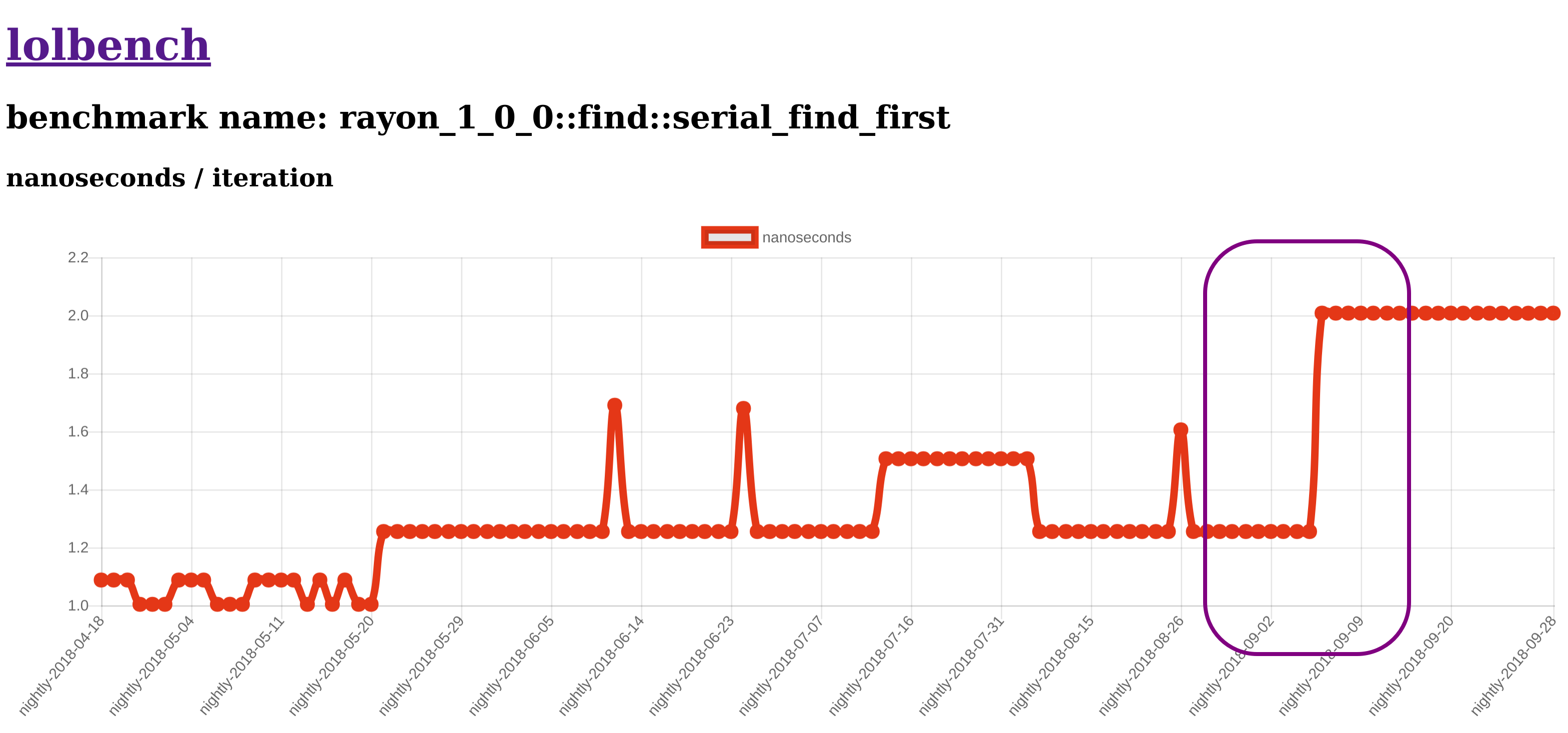
Похоже, что с течением времени в этом тесте произошли некоторые интересные изменения во время выполнения, наиболее очевидным из которых является самый последний регресс, который, похоже, произошел в ночь на 6 сентября 2018 года. Если вы посмотрите дальше на этой странице, вы также можете увидеть другие метрики, которые мы собираем, такие как количество инструкций, количество пропусков ветвлений и кеширования и другие. По моему опыту, очень полезно иметь дополнительные показатели, которые помогут вам первопричинить изменение производительности. Однако эта регрессия была настолько очевидной, что анализировать другие числа не представлялось смыслом.
Деление очевидной регрессии пополам
Мы хотим знать точную фиксацию, вызвавшую проблему, по нескольким причинам. Обычно лучше понять как можно больше об измерении эффективности, прежде чем действовать на его основе, и построение правдоподобного повествования, подкрепленного доказательствами, - один из самых четких способов быть уверенным в любых изменениях, которые мы вносим на основе наших открытий.
Сосредоточившись на ночь 09-06, есть несколько коммитов, которые могут быть причиной этого. Надеемся, что в ближайшем будущем lolbench сможет запускать тесты для каждого PR, слитого в master, но пока мы будем использовать инструмент под названием cargo-bisect-rustc, чтобы найти точную фиксацию, вызывающую замедление. Вот команда, которую я выполнил, чтобы разделить эту регрессию пополам:
❯ cargo bisect-rustc --by-commit --start 2018-09-05 --end 2018-09-06 \
--prompt --preserve-target --test-dir benches/rayon_1_0_0/ \
-- run --release --bin find-serial-find-first
Немного разбив это:
--by-commit говорит, что нужно анализировать ночные даты из наших начальных / конечных флагов, но по-прежнему запускать нашу команду для каждой фиксации слияния между ними.
- --prompt позволяет нам вручную решать, является ли каждый результат теста «базовым» результатом или «регрессивным» результатом, что важно для оценки результата того, что обычно является очень шумным стохастическим процессом. Мы также можем повторить команду несколько раз, если хотим еще больше убедить себя, что видим точное измерение.
- --preserve-target говорит о сохранении целевого каталога для данной инструментальной цепочки между запусками. Обычно Cargo-bisect-rustc используется для тестирования вещей, когда вы хотите повторно запускать компиляцию для каждой попытки, и поэтому целевой каталог очищается между запусками по умолчанию. С тестами я обычно предпочитаю экономить время и предполагать, что компиляция завершится успешно и будет стабильно. Если это так, нам не нужно перекомпилировать двоичный файл для каждой попытки.
- --test-dir устанавливает текущий рабочий каталог для подкоманды cargo, которая передается после голого -, где также при необходимости клонируется репозиторий rust и создаются целевые каталоги для каждой цепочки инструментов.
Вот как это выглядит, если ваш начальный каталог является последней проверкой lolbench. Я немного подправил запись, чтобы удалить вывод фаз "загрузка rustc / std", потому что они сделали загрузку yuuuge без особой ценности. Я также не включил сюда никаких повторных попыток, но на практике я обычно запускаю тест на каждой инструментальной цепочке 3 раза и записываю результаты, чтобы быть более уверенным при принятии решения, действительно ли числа, которые я вижу, регрессируют для каждой фиксации.
We end with a line like so:
regression in f68b7cc59896427d378c9e3bae6f5fd7a1f1fad9
Некоторые любительские мерзавцы:
❯ git show f68b7cc59896427d378c9e3bae6f5fd7a1f1fad9
commit f68b7cc59896427d378c9e3bae6f5fd7a1f1fad9
Merge: 1c2e17f4e3 e1bd0e7b4e
Author: bors <bors@rust-lang.org>
Date: Wed Sep 5 00:37:03 2018 +0000
Auto merge of #53027 - matklad:once_is_completed, r=alexcrichton
...
Итак, теперь мы знаем вероятную причину проблемы - PR, изменяющий std::sync::Once, очень широко используемый примитив синхронизации.
Построение повествования
Запрос на извлечение № 53027 добавил новый нестабильный API в Once путем рефакторинга идентичных ветвей из отдельных методов в новый метод, который также является общедоступным. Вот суть изменения. Дополнительные мега-бонусные баллы, если вы можете угадать, не читая PR-комментарии или пропуская вперед, какая деоптимизация здесь произошла, и все баллы, если вы можете догадаться, почему это произошло.

Фото: закончен исходник
Моя интуиция заключалась в том, что новый метод не удалось встроить, что привело к неспособности оптимизировать дополнительную ветвь и вызов. По-видимому, этого достаточно, чтобы вызвать 60% -ную регрессию в тесте, который находится на стабильном базовом уровне 1,0–1,3 наносекунды на моем текущем оборудовании.
Если вы не знакомы с внутренним устройством или оптимизацией компилятора, не беспокойтесь! Хотя следующие несколько абзацев будут плотными.
Встраивание - это оптимизация «шлюза» в том смысле, что она важна, поскольку позволяет оптимизатору разблокировать дальнейшие улучшения, одновременно рассуждая о функциях вызывающего и вызываемого абонентов. В этом случае перенос проверки равенства в отдельный метод технически создает две ветви: сначала для проверки, если self.state == COMPLETE, а затем для проверки, является ли self.is_completed() == true. Включение self.is_completed() в call_once позволяет компилятору доказать, что две ветви эквивалентны, и объединить эти проверки в одну. В целом, встраивание невероятно важно для производительности в программах на Rust, поскольку оно должно произойти до того, как любая из очень высоких башен абстракций Rust может быть свернута в эффективную реализацию.
Однако сначала меня смутила эта гипотеза, потому что я упустил тот факт, что нам, вероятно, не удалось встроить is_completed в экспортированный универсальный метод. eddyb указал на это несоответствие, чтобы прояснить, почему это произошло. Несмотря на то, что метод is_completed определенно достаточно мал, чтобы быть встроенным LLVM при нормальных обстоятельствах, общие методы, такие как call_once, не оптимизируются и не компилируются до тех пор, пока они не будут «мономорфизированы» или пока не будет создана специализированная версия с конкретными типами. замена общих заполнителей. В случае общих методов и функций, которые экспортируются из определяющего их крэйта, это означает, что они мономорфизируются, оптимизируются и компилируются во время компиляции потребляющего или «нисходящего» крэйта. Кроме того, в Rust перекрестное встраивание неуниверсальных функций и методов в настоящее время поддерживается только в том случае, если они явно аннотированы атрибутами #[inline] или #[inline (always)]. Осведомленные стороны говорят мне, что это требование может быть легче отменить, когда приземляются RLIB, работающие только с MIR, но пока это так.
Конечным результатом этого является то, что если вы извлечете код из горячего пути экспортированной универсальной функции или метода, чтобы поместить его в неуниверсальную функцию или метод, вы можете в конечном итоге заблокировать оптимизацию, которая имела место ранее. Что, по-видимому, и произошло в данном случае. Хотя воздействие очень-очень-очень маленькое, этот примитив действительно распространен в экосистеме. И каждая мелочь имеет значение, когда дело доходит до достижения стремления стать самым быстрым языком, который (с заглавной буквы O, мнение) по-прежнему действительно приятно использовать!
В конечном счете, я решил сосредоточиться на сообщении об этом изменении для этого поста отчасти потому, что улавливание регрессий в стиле «смерть на тысячу сокращений», подобных этой, - это та область, в которой, я надеюсь, lolbench может со временем преуспеть по сравнению с текущим состоянием искусство, но еще и потому, что он достаточно прост, чтобы поместиться и в качестве тестового полета для проекта, и в качестве примера для этой публикации.
Отчетность
Конечно, я планировал развернуть красную ковровую дорожку с красиво отформатированным небольшим отчетом в новом выпуске GitHub, чтобы оправдать необходимость в последующих действиях (что-то, что я бы хотел немного автоматизировать, так как отчеты об ошибках перфоманса содержат много общие вещи), и eddyb оставил комментарий по этому поводу, когда я шла спать. Поскольку это было простое исправление, казалось, что никто не чувствовал себя обязанным запрашивать числа, и теперь в очереди слияния есть PR, чтобы исправить регресс. Пока я пишу это, PR еще не появился, а это значит, что lolbench еще не запустил тесты для ночного репортажа, содержащего его. Я также еще не написал код, чтобы легко указать lolbench на несвязанный PR для тестирования.
Но было бы действительно неплохо похвастаться тем, насколько все это круто и как все застегивается. Вы говорите, что это? Вы, дорогой читатель, не могли бы пока принять какое-нибудь заменяющее доказательство? Хорошо, давайте посмотрим, смогу ли я проверить это изменение на своей машине локально.
(Определенно не эго) Проверка
Мы измеряем эталонный тест здесь трижды: по одному разу с помощью nightly-09-05 и nightly-09-06, чтобы предоставить контекст для оборудования, которое я использую, а затем один раз с помощью набора инструментов, созданного на основе текущей подсказки мастера с помощью применено исправление последующего PR. Локальная цепочка инструментов - это моя рабочая копия Rust со следующим патчем:
diff --git a/src/libstd/sync/once.rs b/src/libstd/sync/once.rs
index ce54726bae..17cb614ba1 100644
--- a/src/libstd/sync/once.rs
+++ b/src/libstd/sync/once.rs
@@ -330,6 +330,7 @@ impl Once {
/// assert_eq!(INIT.is_completed(), false);
/// ```
#[unstable(feature = "once_is_completed", issue = "42")]
+ #[inline]
pub fn is_completed(&self) -> bool {
// An `Acquire` load is enough because that makes all the initialization
// operations visible to us, and, this being a fast path, weaker
Вот где мы заканчиваем:
❯ for toolchain in nightly-2018-09-05 nightly-2018-09-06 local
echo "running benchmark with $toolchain"
echo
cargo +$toolchain run --release --quiet --bin find-serial-find-first | grep 'time:'
echo
end
running benchmark with nightly-2018-09-05
time: [1.2689 ns 1.2727 ns 1.2783 ns]
running benchmark with nightly-2018-09-06
time: [2.0291 ns 2.0326 ns 2.0370 ns]
running benchmark with local
time: [1.3047 ns 1.3064 ns 1.3083 ns]
Средние числа в каждой строке представляют собой наилучшую оценку критерия для среднего времени выполнения функции, а левое и правое числа представляют 95% доверительный интервал вокруг этой оценки. Другими словами, это попытка получить разумные планки погрешностей, и ни одна из планок погрешностей для трех измерений не перекрывается, что является хорошим трэйтом того, что наши измерения надежны.
Мне кажется, это исправление почти полностью компенсирует потерю производительности! Посмотрим через пару дней, согласится ли lolbench. В будущем я хотел бы углубиться в точные изменения кодогенератора, которые оставляют эти 0,3 нс на столе, но я думаю, что это расследование на другой день :).
Вы обещали рассказать, почему эта проблема важна
Это не подходящий заголовок для сообщения в блоге или вопроса, но да, спасибо за напоминание.
Старый заклятый враг, пересмотренный
В январе 2016 года текущим стабильным выпуском был Rust 1.8, и мне нравится думать, что Нико Мацакис, лидер команд Rust и виртуозный хакер компиляторов, был в более невинное время в своей жизни, чем сегодня. Я, конечно, был. Он опубликовал проблему на GitHub, говоря:
Нам нужен набор тестов, ориентированный на время выполнения сгенерированного кода.
Прочитав это, я написал пару сообщений (ветка reddit 1) (ветка reddit 2), в которой подробно описаны мои усилия по сбору некоторых тестов и выявлению явных изменений производительности в двоичных файлах, созданных различными ночными изданиями. Данные были слишком шумными, чтобы их можно было автоматизировать и обрабатывать. Затем, примерно через два года после своего первого поста, в феврале этого года Нико написал на irlo с просьбой о помощи в возобновлении работы над проектом и размещении результатов на perf.rlo. Я такой лох. К счастью, я был еще и бездельником, который за это время узнал немного больше о том, как работают компьютеры.
Просто закончите манифест
Rust - это быстрый язык программирования. Таким образом, программы на Rust работают «быстро», особенно если вы пишете их с правильными наблюдениями за тайными лей-линиями рождения и смерти, известными как «время жизни», а также не забываете передавать Cargo флаг --release. Не вдаваясь в подробности того, что именно означает «быстрый», общепризнанной культурной ценностью в сообществе Rust является то, что код, предоставленный для rustc, должен приводить к созданию «быстрых» программ. И, само собой разумеется, что если вы обновляете свой компилятор с помощью полуторного ритуала, компилятор должен создавать программы, по крайней мере, так же «быстро», как и раньше.
Также важное значение в сообществе Rust - правило разработки программного обеспечения, не относящееся к ракетостроению:
автоматически поддерживать репозиторий кода, который всегда проходит все тесты
Это подход к тестированию, который во многих отношениях очень хорошо послужил проекту Rust, и, на мой взгляд, реализация этого подхода является действительно важным фактором успеха Rust на сегодняшний день. См. Сообщение Брсона о тестировании проекта Rust для получения более подробной информации, но обратите внимание, что на момент написания этой информации около года назад.
В интересах сохранения и развития Rust как быстрого языка программирования, можем ли мы предложить, чтобы проект также принял «Правило разработки программного обеспечения, которое больше похоже на ракетостроение»?
автоматически поддерживать репозиторий кода, который всегда сохраняет постоянство или улучшает все тесты
Это действительно очень сложно по целому ряду причин. Или, как мне сказали профессионалы, довольно сложно.
Хорошо, может быть, мы могли бы попробовать «Правило разработки программного обеспечения, похожее на ракетостроение»?
автоматически поддерживать репозиторий кода, где вы всегда будете получать уведомления, если производительность теста ухудшается
Это аналог афоризма «вы не можете управлять тем, что не измеряете» и реализован сегодня для времени компиляции в форме perf.rlo, который измеряет время компиляции для ряда проектов с использованием компиляторов, созданных на основе каждого слияния. освоить. Есть сопутствующий бот, который также может быть вызван в PR перед объединением, чтобы увидеть, какое влияние изменения могут иметь на время компиляции ниже по течению.
Я упоминал, что точное и точное измерение небольших тестов действительно сложно? Особенно в наши дни со всеми этими новыми причудливыми вещами, такими как «иерархия памяти», «генераторы псевдослучайных чисел», «ввод / вывод» и «многопроцессорность».
Итак, как это делается?
Изначально я намеревался написать здесь очень длинный раздел, чтобы описать ряд проблем и способов их устранения, которые мы принимаем в процессе получения этих результатов. Однако, публикуя черновик сообщения, я случайно включил черновик в RSS-канал своего блога (упс! Так как исправлено), и теперь его читает куча людей! Захватывающе!
Вместо того, чтобы торопиться, пытаясь все исправить, я отложу этот раздел и напишу техническую документацию по проекту. Я буду писать в блоге еще раз, когда сделаю это. Если вам просто не терпится узнать больше об усилиях, которые прилагает lolbench для получения точных данных, тем временем вы можете посмотреть мой доклад об этом в мае. Качество записи не самое лучшее, но я думаю, что в нем есть хороший контент.
Rust - это мы, Rust должен быть быстрым, мы должны быть быстрыми
Сюда скорее! Приходите на помощь! Мне потребовалось довольно много времени, чтобы собрать это воедино, и это только начало. Теперь, когда это запущено и работает непрерывно, нам нужно получить больше данных, лучше понять, какие данные у нас есть, и начать сортировку и исправление регрессий производительности, влияющих на сообщество.
Я надеюсь, что в ближайшем будущем мы сможем запускать lolbench для каждого слияния с Rust, а не только для ночных сборов, добавлять множество тестов по мере того, как мы обнаруживаем различные типы покрытия кода, которые нам нужны, и уточняем анализ и отчетность, чтобы предотвратить пропущенные регрессии. и свести к минимуму ненужную работу по сортировке из-за ложных срабатываний.
В будущем, о котором я мечтал только при лихорадке, lolbench может автоматически проверять вероятные аномалии между несколькими участниками тестов, запускать тесты, используя множество потенциальных флагов компилятора, и сравнивать их, может автоматически уведомлять нас, если два теста статистически эквивалентны, и мы можем отключить один, чтобы получить статистику распределения кучи и графы пламени для каждой тестовой функции и т.д. и т.д.
Если вас интересуют подобные вещи, приходите и проверяйте открытые вопросы в репозитории или пишите мне на IRC - я участник # wg-codegen на irc.mozilla.org. Я очень рад услышать от вас!