 Dudochkin Victor
Dudochkin Victor
Мой опыт переписывания Enjarify на Rust
Перевод | Автор оригинала: Robert Grosse
В прошлом году я решил переписать Enjarify (приложение Python для командной строки) на Go и делать заметки, чтобы получать данные, сравнивающие языки. Очевидно, что при переписывании существующего проекта результирующий код не будет таким идиоматическим, как проект, написанный с нуля, но я подумал, что это справедливо, поскольку суслики по какой-то причине постоянно пытаются отвести людей от Python и делают rewrite позволяет проводить параллельное сравнение. Enjarify также имеет преимущество сквозного тестирования, позволяя легко проверить, что реализации фактически эквивалентны.
В любом случае, чем больше я использовал Go, тем больше я его ненавидел, и в итоге я отказался от проекта. Недавно я заинтересовался Rust и решил закончить переписывание Go и переписать Enjarify в Rust, чтобы получить больше опыта с Rust и посмотреть, не перестану ли я ненавидеть его, как это было с Go. Ниже мой опыт, а также сравнение трех версий.
Весь обсуждаемый код доступен здесь.
Скорость
Во-первых, сравнение производительности. Для этого я проверил хеш-тесты Enjarify в качестве теста. Это тест, который включает в себя перевод каждого тестового apk для всех возможных комбинаций параметров и хеширование результатов для обнаружения регрессий. Я использовал CPython 3.4.3, Go 1.7 и Rust nightly (2016–09–02), все они работали на i7–4790 с Linux.
Обратите внимание, что в этом тесте измерялась однопоточная производительность. Я заметил, что при настройках по умолчанию версия Go использовала 130–160% ЦП, несмотря на то, что в коде не было никаких горутин. Я думаю, это потому, что сборщик мусора работает в отдельной горутине, запущенной средой выполнения. Во всяком случае, я проводил тесты с GOMAXPROCS = 1, что привело к замедлению ~ 8% по сравнению с многопоточной версией.
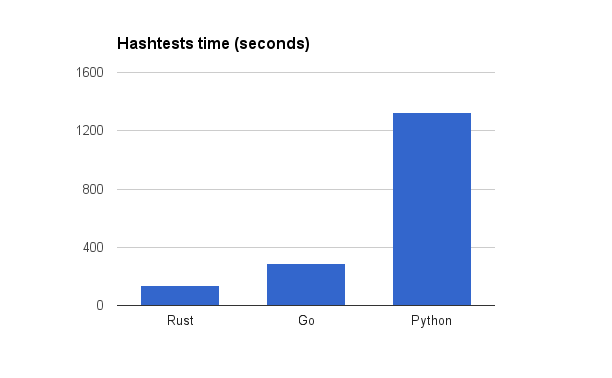
Время хеш-тестов: Rust 135 секунд, Go 290 секунд, Python 1328 секунд
Вот диаграмма, показывающая ускорение по сравнению с Python (т. Е. Обратно).
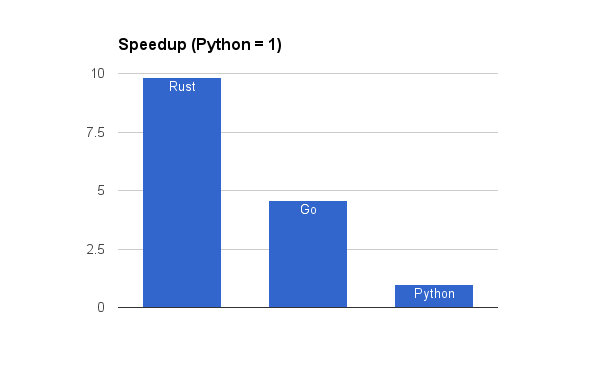
Ускорение: Rust: 9,8x, Go 4.6x, Python 1.0x
Неудивительно, что Python медленнее Go, а Go медленнее Rust. Однако я был удивлен тем, насколько велик был разрыв, особенно между Go и Rust. Я думаю, что все эти аннотации на время жизни и долгое время компиляции действительно окупаются. Я думаю, это подчеркивает, что Go не находится на том же уровне «системного» языка, как C++ и Rust.
Прежде чем все суслики выйдут из строя, чтобы сказать что-то вроде «вы можете избежать кучи в Go, если вы действительно попытаетесь», версия Rust реализует более или менее тот же код, так что это не имеет значения в любом случае. Я не делал версию Go намеренно неэффективной - я просто пытался написать что-то эквивалентное исходному Python самым простым и естественным способом, который поддерживает каждый язык. Я ожидаю, что большая часть выигрыша в Rust связана с оптимизацией, которая невозможна или неосуществима в Go из-за таких функций, как время жизни, неизменяемость и обобщения, или вещей, которые неприемлемо увеличивают время компиляции в Go (например, LLVM). Кроме того, в версии Rust еще есть много возможностей для оптимизации.
^ Обновление: я потратил некоторое время, пытаясь оптимизировать код Go и Rust, и написал следующий пост с результатами.
Я надеялся включить в это сравнение Pypy, но, к сожалению, он оказался намного медленнее, чем даже CPython. Pypy 3 раньше был в несколько раз быстрее, чем CPython, но похоже, что в прошлом году производительность резко упала и до сих пор не восстановилась. Думаю, мне следует перестать рекомендовать людям использовать Pypy с Enjarify.
Размер кода
Чтобы измерить размер кода, я вырезал комментарии, начальные и конечные пробелы и сложил длину каждой непустой строки. Я исключил сгенерированный код, но включил код для его создания. Сценарий находится здесь, если вы хотите увидеть точную методологию.
Изображение:
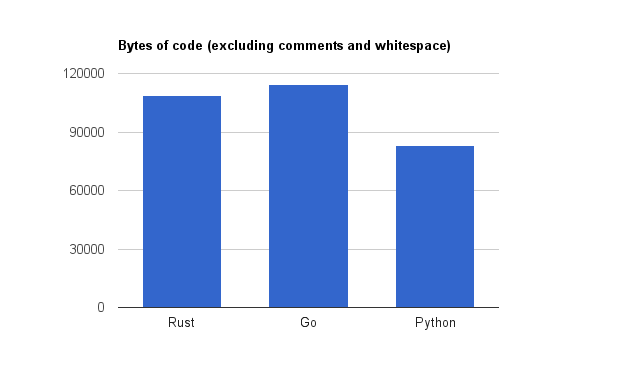
Байты кода: Rust 108847, Go 114180, Python 83013
Python, Rust и Go имели 2876, 3783 и 4971 строк кода соответственно. Соответствующее количество символов - 83013, 108847 и 114180. Я думаю, что последний - лучший показатель, поскольку он менее чувствителен к стилю скобок, но в любом случае код Rust был больше, чем Python, но меньше, чем Go.
Неудивительно, что Go самый многословный. То, что Rust теряет из-за аннотаций времени жизни и больших сигнатур универсальных типов, он выигрывает от акцента на эргономике и наличия реальных абстракций, вместо того, чтобы требовать от вас постоянно копировать и вставлять код. С другой стороны, по лаконичности Rust и близко не может приблизиться к Python, что имеет смысл, поскольку Python - это язык сценариев с динамической типизацией.
Время разработки
Перезапись Go заняла около 45 часов. Перезапись в Rust заняла 49 часов. Обратите внимание, что эти числа смещены в сторону Rust, потому что у меня было то преимущество, что я мог консультироваться с кодом Python и Go при написании версии Rust, а также преимущество в том, что я уже решил некоторые проблемы, возникшие во время перезаписи Go.
Я думаю, что важным выводом является то, что переписывание вещей занимает больше времени, чем вы ожидаете, и что это занимает много времени независимо от задействованных языков.
Во время переписывания Rust я потратил много времени на поиск точных имен и синтаксиса методов в Vec, Option, HashMap и т.д. В отличие от Go, встроенных методов вообще нет. Иногда я выполнял поиск в Интернете, чтобы попытаться найти самый чистый способ сделать что-нибудь в Go, только чтобы обнаружить, что это невозможно, и что вам просто нужно использовать грубую силу с помощью ограниченных доступных инструментов.
Я также столкнулся с несколькими непостижимыми ошибками времени жизни / заимствования, но по мере того, как я пошел, это стало легче и составило всего около двух часов потраченного впустую времени. Я думаю, что самая большая потеря времени в Rust была своего рода смертью от тысячи сокращений - все время, потраченное на попытки получить амперсанды и ссылки в нужных местах, и другие легко исправляемые, но очень частые ошибки компилятора.
Однако это показывает, что печально известная кривая обучения Rust не так уж плоха, особенно по сравнению с широко разрекламированной простотой Go. Кроме того, знакомство с языком - это, по сути, единовременные затраты. Я не удивлюсь, если бы обнаружил, что если бы этот эксперимент был проведен кем-то, кто является экспертом в Go и Rust, а не новичком, версия Rust была бы завершена быстрее, чем версия Go.
Ошибки
Поскольку первоначальной мотивацией для переписывания было сравнение Go и Python, я тщательно отслеживал количество ошибок времени выполнения в версии Go, чтобы предоставить немного данных для постоянных дебатов о статической и динамической типизации, и решил, что с таким же успехом могу сделать это. то же самое и с Rust.
В версии Go было 50 ошибок, которые были обнаружены во время тестирования после прохождения компилятора. Сюда входят как тривиальные ошибки, так и несколько ошибок, на отладку каждой из которых уходило 30+ минут. Для Rust соответствующее число - 29. Это не включает 3 преднамеренных целочисленных переполнения, в которых я забыл использовать операции обертывания, поскольку это не повлияет на корректность сборки релиза. Случаи, когда переполнение представляло собой реальную ошибку, включены в 29.
Я надеялся, что сильная статическая типизация в Rust поможет уменьшить количество ошибок, но, к сожалению, особого эффекта это не дало. Пара ошибок, с которыми я столкнулся в Go, совершенно невозможны в Rust, но в версии Rust все еще было множество ошибок. Отчасти проблема заключается в том, что ошибки, возникающие при переписывании кода, отличаются от ошибок, возникающих при нормальном кодировании. В данном случае я копировал код, который уже был правильным, поэтому большинство ошибок возникло из-за неосторожных ошибок транскрипции, которые никакая система типов не могла бы уловить.
Однако есть еще один способ, которым язык влияет на количество ошибок - это умственная нагрузка, возникающая при переводе кода. Например, рассмотрим следующие строки Python.
if isinstance(instr, ir.RegAccess) and not instr.store:
used.add(instr.key)
В Rust это стало
if let ir::RegAccess(ref data) = instr.sub {
if !data.store {
used.insert(data.key);
}
}
Однако изначально я забыл включить проверку! Data.store, что привело к ошибке. Проблема в том, что в Rust нет способа выполнить требуемое «приведение вниз» как часть более крупного выражения *. Написав внешний if let, я пошел побрить яка и совершенно забыл ввести вторую половину условия if. Если бы понижение было простым выражением, которое я мог бы печатать без перерыва, этого почти наверняка бы не произошло.
^ Позже я узнал о спичечных охранниках, которые, вероятно, могли бы справиться с этим, но в то время я не знал о них.
Проблемы реализации
В Python есть ряд функций, которые требуют более сложного перевода на Go или Rust. Вот краткий обзор того, как я с ними справился.
Наследование
К счастью, в Enjarify есть только два места, где нетривиально используется наследование. Первый и более простой случай - это ConstantPool.
Существует две реализации пулов констант: SimpleConstantPool и SplitConstantPool. Это подклассы абстрактного базового класса ConstantPool, который реализует большую часть функциональности, полагаясь при этом на пару абстрактных методов, реализованных подклассами.
В Go встроенные структуры не могут получить доступ к структуре внедрения, поэтому мне пришлось создать структуру для базового класса и интерфейс, представляющий методы, реализованные в подклассах, а затем сохранить этот интерфейс в базовой структуре. Затем я создал структуру для каждого из подклассов, встраивающих базовую структуру, и интерфейс, представляющий общедоступный интерфейс всего этого. Плюс все методы-оболочки, необходимые для реализации интерфейсов.
К счастью, в Rust методы по умолчанию в трейтах могут вызывать нестандартные методы трейта, что делает возможным прямое моделирование абстрактного базового класса. Версия Rust имеет только одну трэйту и две реализующие структуры, почти идентичные исходному Python. Было только несколько незначительных недостатков - во-первых, у трейтов не может быть полей, поэтому мне пришлось вместо этого использовать метод доступа. Во-вторых, у типажных объектов не может быть общих методов, поэтому я не мог использовать Into для перегрузки (подробнее об этом позже).
Второй и гораздо более сложный случай наследования - это JvmInstruction. У него есть подклассы для различных типов инструкций (Label, RegAccess, PrimConstant, OtherConstant, Switch и Other), а также LazyJumpBase, у которого есть два собственных подкласса (If и Goto). Кроме того, в коде широко используется понижающее преобразование.
Версия Go просто реплицировала иерархию наследования Python, используя интерфейсы и структуры, как и раньше. Однако это оказалось кошмаром, и в любом случае это невозможно в Rust (без каких-либо хаков). В версии на Rust я избавился от LazyJumpBase (дублируя код, который он содержал) и сделал JvmInstruction огромным перечислением.
Было несколько неприятностей при использовании перечисления. Самая большая проблема в том, что для этого требуется много шаблонов и дублирования. Например, вот определение перечисления, которое заменило (большую часть) JvmInstruction.
pub enum JvmInstructionSub {
Label(LabelId),
RegAccess(RAImpl),
PrimConstant(PCImpl),
OtherConstant,
Goto(GotoImpl),
If(IfImpl),
Switch(SwitchImpl),
Other,
}
Если вы хотите иметь возможность ссылаться на содержимое перечисления, иметь именованные поля * или вызывать методы, вам необходимо создать отдельное определение структуры. И это в дополнение к именам конструкторов перечисления, что приводит к множеству повторений.
^ Исправление: варианты перечисления могут иметь именованные поля.
Кроме того, мне нужно было превратить методы, которые были определены в различных подклассах, в методы JvmInstruction с гигантскими операторами сопоставления по содержащемуся перечислению. Я также добавил вспомогательные методы, такие как is_jump и is_constant, поскольку проверки isinstance являются проблемой для системы перечисления.
Исключения
Enjarify использует исключения двумя способами. Во-первых, если сгенерированный байт-код превышает предел файла класса, он генерирует исключение и повторяет попытку перевода со всеми включенными параметрами оптимизации. Во-вторых, если при переводе класса возникает какое-либо другое исключение, оно регистрирует ошибку и переходит к следующему классу, чтобы обработать недопустимые или искаженные классы.
Хорошая новость заключается в том, что std::panic::catch_unwind / resume_unwind в Rust оказалось намного проще в использовании, чем defer / recovery в Go. Плохая новость заключается в том, что Rust распечатывает трассировку стека, когда паника возникает впервые, а не когда паника распространяется на вершину стека, поэтому мне пришлось установить собственный хук паники, чтобы предотвратить это.
Общая изменчивость
Одна вещь, которая меня удивила, заключалась в том, насколько дружественным к заимствованиям уже был Enjarify, учитывая, что он был написан на Python, где псевдонимы и изменчивость являются естественными. Большая часть кода требовала лишь незначительных изменений, чтобы заимствовать проверку, но была пара более сложных случаев.
В первом случае в IRWriter хранится (изменяемая) ссылка на ConstantPool, которая сохраняется до тех пор, пока не будет завершен весь класс. Ссылка на пул на самом деле необходима только при первоначальном создании IR, поэтому я просто разделил и реорганизовал код, что позволило заимствовать чек. Результат стал чище, и я бы сделал то же самое с версией Python, если бы у меня было время, но примечательно, что это потребовало больших изменений в дизайне кода.
Изменение JvmInstruction с коробок на значения и удаление с ним всех использований ссылочной идентичности также устранило еще один большой источник псевдонимов.
Другая проблема, с которой я столкнулся, заключалась в повторяющемся шаблоне, когда я перебираю все инструкции и изменяю каждую, исследуя предыдущие инструкции или две. На самом деле это не нарушает правила псевдонимов, но компилятор не может это узнать. Вместо этого я придумал обходной путь. Я создал локальную переменную вне цикла, которая хранит копию соответствующих данных из предыдущей инструкции, и обновил ее и конец тела цикла.
Последний случай - это CopySetsMap. В этом случае для алгоритма необходима общая изменчивость, поэтому мне просто пришлось поместить все в Rc
Контрольные циклы
И снова я был удивлен тем, насколько мало код действительно полагался на ссылочные циклы. Я был готов плохо имитировать сборку мусора с помощью TypedArenas, но, как оказалось, в дизайне уже не было нетривиальных ссылочных циклов.
Болевые точки в Rust
Хотя в конечном итоге я не возненавидел Rust, я столкнулся с множеством неприятностей. Надеюсь, большинство из них будет исправлено в будущем. Справочный синтаксис сбивает с толку
Почти невозможно угадать, где вам нужны &s, refs и т.д., Особенно при работе с цепочками и замыканиями итераторов. Если вы сможете написать такой код и скомпилировать его с первой попытки, я буду очень впечатлен.
let most_common: Vec<_> = {
let mut most_common: Vec<_> = narrow_pairs.iter().collect();
most_common.sort_by_key(|&(ref p, &count)| (-(count as i64), p.cmp_key()));
most_common.into_iter().take(pool.lowspace()).map(|(ref p, count)| (*p).clone()).collect()
};
for k in most_common.into_iter() {
narrow_pairs.remove(&k);
pool.insert_directly(k, true);
}
Почему &s, * s и refs идут туда, где они находятся? ¯ \ _ (ツ) _ / ¯
Отчасти проблема заключается в том, что auto-deref означает, что вы можете обойтись без правильных deref в одних обстоятельствах, но в других сделать то же самое не удается по непонятной причине.
Что еще хуже, существует огромная несогласованность в том, что одни методы принимают ссылки, а другие принимают значения. Это действительно имеет смысл, если подумать. Например, map insert() и entry() становятся владельцем ключа, потому что им может потребоваться его вставить, в то время как remove(), [], contains_key() и т.д. Не требуют владения и, следовательно, принимают ссылки для максимальной гибкости. . Однако это все еще дополнительное бремя, с которым нужно бороться в начале, особенно когда вы имеете дело только с простыми типами копирования и вам не о чем беспокоиться.
Компилятор в значительной степени сообщает вам, что вам нужно изменить, но я бы хотел, чтобы мне не пришлось так часто проходить цикл редактирования -> компиляция -> редактирование -> компиляция -> успешный цикл. Это смерть от тысячи порезов, о которых я упоминал выше.
Явные целочисленные приведения
Все эти целочисленные преобразования раздражают в Go, и они раздражают и в Rust. Одна из проблем заключается в том, что он заставляет вас постоянно выбирать между использованием целочисленного типа, представляющего фактический диапазон сохраняемых значений, и использованием типа, который наиболее удобен с синтаксической точки зрения (т. Е. Просто везде используется usize). Частично это связано с тем, что большинство значений, с которыми работает Enjarify, конкретно ограничены 16 или 32 битами из-за формата файла Dalvik. Я полагаю, что для приложений, которые не выполняют синтаксический анализ двоичных файлов, гораздо реже иметь априорные ограничения в значениях.
Я также хочу, чтобы семантика переполнения могла быть отделена от размера хранилища. Rust идет в этом направлении, требуя явных операций обертывания, когда требуется переполнение, но для полного решения, вероятно, потребуются зависимые типы. Кстати, я нахожу удивительным, что при сужении не проверяется переполнение. Это похоже на оплошность, хотя это может быть слишком сложно сделать в LLVM или в чем-то еще.
Хуже всего то, что он кажется неэффективным для предотвращения ошибок. В версии Rust было несколько ошибок, связанных с приведением типов целых чисел. В одном случае я вызвал не ту функцию, и она заняла другую ширину, чем желаемая функция. Но он прошел компилятор, потому что я также забыл преобразовать рассматриваемые переменные.
Кроме того, когда почти для каждого вызова требуется приведение типов, люди просто автоматически добавляют их, чтобы выключить компилятор, что противоречит цели.
Синтаксис подтипа времени жизни не обнаруживается
Комбинация исключения времени жизни и автоматического вывода ковариации означает, что вам редко требуется более одного параметра времени жизни. Но в случае, когда вы это делаете, требуемый синтаксис не обнаруживается.
Например, моя структура IRBlock хранит изменяемое заимствование объекта ConstantPool, но ссылки, хранящиеся в пуле констант, должны пережить заимствование, а это означает, что требуется несколько параметров времени жизни. Просто указать несколько параметров времени жизни несложно. То, что я нашел невозможным, заключалось в том, чтобы указать, что одна из жизней переживает другую. Оказывается, требуется синтаксис
struct IRBlock<'b, 'a: 'b> {
pool: &'b mut (ConstantPool<'a> + 'a),
// other fields omitted
}
Дополнительная граница и круглые скобки на объекте-трэйте достаточно сбивала с толку, но элемент "a:" b не упоминался ни в одном из руководств или руководств, которые я смог найти. Фактически, единственная причина, по которой я это понял, - это то, что я наткнулся на нее в вопросе о переполнении стека, касающемся косвенно связанной темы (могут ли структуры иметь предложения where).
Обратите внимание, что обычно полезный компилятор здесь совершенно бесполезен. Кажется, что предложения компилятора смещены в сторону наличия как можно меньшего количества параметров времени жизни, поэтому, если вы здесь что-то испортите, в появившемся сообщении об ошибке компилятора будет предложено удалить второй параметр времени жизни, что, очевидно, неверно в данном случае.
Отсутствие перегрузки
В Rust идиоматично использовать общие параметры Into для перегрузки методов, но, к сожалению, я не мог этого сделать ни в одном из случаев, когда это было наиболее полезно.
ConstantPool работает с Cow
fn _class(&mut self, s: Cow<'a, bstr>) -> u16 {
let ind = self._utf8(s);
self.get(Class(ArgsInd(ind)))
}
fn class(&mut self, s: &'a bstr) -> u16 {self._class(s.into())}
Точно так же мой TreePtr (разреженный постоянный массив, реализованный в виде дерева) использует usize для внутренней индексации, но вызывающие стороны всегда используют u16, поэтому было бы неплохо справиться с этим. К сожалению, usize по необъяснимым причинам не может реализовать From
Я предполагаю, что идея usize не быть From
Плохая поддержка байтовых строк
Поскольку большая часть данных, с которыми работает Enjarify, - это не utf8, я не мог использовать собственные строковые типы Rust. Вместо этого я просто определил псевдонимы типов для байтовых строк и использовал их везде.
pub type BString = Vec<u8>;
pub type bstr = [u8];
Это работает достаточно хорошо, главным образом потому, что я не делаю особых манипуляций со строками, кроме нарезки и конкатенации. Но в тех редких случаях, когда я это делаю, я действительно упускал из виду удобные строковые методы, которые не определены для Vec
Кстати, я так и не понял, как заставить компилятор замолчать насчет именования bstr, несмотря на неоднократные поиски. Ничего из того, что я пытаюсь, похоже, не работает.
Обновление: ответ оказывается #[allow (non_camel_case_types)]. Не знаю, как я это пропустил. Я пробовал несколько вариантов, например #[allow (non_camel_case)], но не пробовал ставить _types в конце.
Ссылка на равенство многословна
В Rust все использует равенство значений, что обычно и нужно вам. Но в тех случаях, когда вам нужно ссылочное равенство, это излишне многословно. Не существует эквивалента оператора is в Python.
Это приводит к такому коду
pub fn is(&self, rhs: &Self) -> bool {
match (self.0.as_ref(), rhs.0.as_ref()) {
(None, None) => true,
(Some(r1), Some(r2)) => r1 as *const _ == r2 as *const _,
_ => false
}
}
или даже хуже,
fn ptr(p: Option<&Rc<RefCell<CopySet>>>) -> *const CopySet {
match p {
Some(p) => p.deref().borrow().deref() as *const _,
None => null(),
}
}// ... let s_set = ptr(self.0.get(&src));
let d_set = ptr(self.0.get(&dest));
if !s_set.is_null() && s_set == d_set {
// src and dest are copies of same value, so we can remove
return false;
}
Написав это, я понял, что это можно упростить, просто взяв указатель на внешний RefCell, но в любом случае это все равно неоправданно сложно.
Нет подмножеств перечислений
Когда у вас есть значение типа перечисления, оно обрабатывается так, как если бы оно могло быть любым вариантом перечисления, но часто вы статически знаете, что это подмножество полного перечисления. Обычно это вызывает лишь незначительные затруднения с проверкой полноты, но становится намного более раздражающим, когда варианты перечисления имеют разные ограничения.
Например, с перечислением constantpool::Entry вариант Utf8 хранит Cow <’a, bstr>, но любой другой вариант хранит просто пару целых чисел. Тем не менее, у enum есть целое, внезапно требуется параметр времени жизни повсюду, и он больше не может быть Copy, даже если статически известно, что он не является Utf8. Проблема с параметром времени жизни может быть решена до некоторой степени, просто используя «статическое время жизни» в этих местах, но нет никакого способа волшебным образом заставить его Копировать.
Очевидно, что подмножества типов значительно усложнили бы систему типов, и я даже понятия не имею, какой синтаксис вы бы использовали для их определения. Но это все равно немного раздражает.
Проверка полноты соответствия не обрабатывает целые числа
По какой-то причине, даже если вы соответствуете u8 и охватываете все случаи от 0 до 255, вам все равно нужно добавить _ => unreachable!() В конце, чтобы удовлетворить компилятор. Я не уверен, почему это не обрабатывается, но это как бы противоречит цели проверки полноты. При недостижимом кейсе по умолчанию нет защиты во время компиляции в случае, если вы законно пропустили кейс. Судя по всему, это известная проблема, но ее нельзя исправить из-за обратной совместимости.
Лексическое время жизни
Я знаю, что над нелексическим временем жизни активно работают, но я подумал, что с таким же успехом могу выделить некоторые случаи, когда ограничения текущей системы заимствования вызывали неудобный код.
let t = self.prims.get(src); self.prims.set(dest, t);
let t = self.arrs.get(src); self.arrs.set(dest, t);
let t = self.tainted.get(src); self.tainted.set(dest, t);
Например, здесь мне пришлось разделить вызовы и назначить их временной переменной. Лексическое время жизни запрещает гораздо более естественное вложение выражений, поскольку изменяемое заимствование внешнего вызова метода включает оценку аргументов метода.
Я не уверен, связано ли это, но я также столкнулся со странной проблемой, когда Box::заимствовать_mut() не работает, а ручное повторное заимствование работает. Это на самом деле меня настолько озадачило, что мне пришлось прибегнуть к вопросу о переполнении стека.
Массивы клонов не являются клонами
По какой-то причине массивы T: Clone нельзя клонировать. Смешно, что мне приходится писать такой код
fn clone<T: Clone>(src: &[T; 16]) -> [T; 16] {
[src[0].clone(), src[1].clone(), src[2].clone(), src[3].clone(), src[4].clone(), src[5].clone(), src[6].clone(), src[7].clone(), src[8].clone(), src[9].clone(), src[10].clone(), src[11].clone(), src[12].clone(), src[13].clone(), src[14].clone(), src[15].clone()]
}
Похожая проблема делает невозможным инициализацию большого массива, вынуждая меня использовать Vec внутри SplitConstantPool, даже если данные имеют известную фиксированную длину.
Отсутствующие функции
Я не знаю, упускаю ли я что-то *, но мне не удалось найти никаких вспомогательных методов для копирования или клонирования элементов в цепочке Option или итератора. Его можно решить с помощью закрытий, таких как .map (| x | x) (или его двоюродный брат .map (| ref x | x.clone())), но это кажется глупым и ненужным.
^ Обновление: мне что-то не хватало.
Точно так же кажется, что Vec<Option
^ Обновление: вы можете фильтровать и отображать с помощью одного вызова.
Еще одна вещь, которую я упустил, - это отсутствие эквивалента int.bit_length() в Python. У целых чисел есть метод lead_zeros(), но без возможности автоматического получения соответствующей ширины это может привести к ошибкам. Это не праздное беспокойство, потому что одна из 29 ошибок, с которыми я столкнулся, была написана
(64 - part63.leading_zeros())
Для того, что оказалось 32-битной переменной, а не 64-битной, как я думал.
Сторонние зависимости
В версиях Python и Go использовалась только стандартная библиотека, но для версии Rust мне пришлось использовать несколько крэйтов сторонних производителей. В частности, byteorder, getopts, lazy_static, rust-crypto и zip. Cargo делает это очень легко, но вам все равно придется потратить дополнительное время, чтобы выбрать крэйт и прочитать документацию, а зависимости от третьих лиц заставляют меня немного нервничать (см. Фиаско с левой клавиатурой).
Кроме того, почтовый крэйт выполняет только базовые функции. Например, может быть полезно использовать фиксированную метку времени для выходных jar-файлов, чтобы сделать выходные данные детерминированными. Python и Go поддерживают это, но почтовый крэйт не поддерживает.
Когда раньше люди говорили, что Go включает батарейки или имеет обширную стандартную библиотеку, я всегда насмехался, поскольку трудно серьезно относиться к стандартной библиотеке, когда в ней даже нет коллекций, но теперь я понимаю, что они имеют в виду. В Rust есть множество полезных коллекций и стандартных алгоритмов, но почти ничего другого, в то время как Go - наоборот. У Python, конечно же, есть и то, и другое.
Нет попытки! для варианта
Для Rust-версии декодера mutf8 я использовал специальные адаптеры итератора. Итераторы возвращают Options, а не Results, но, к сожалению, нет эквивалента try! макрос для Option. Это означало, что мне приходилось копировать и вставлять одни и те же четыре строки кода снова и снова, как вы можете видеть ниже.
impl<'a> Iterator for FixPairsIter<'a> {
type Item = char;
fn next(&mut self) -> Option<char> {
let x = match self.0.next() {
None => { return None; }
Some(v) => v
};
if 0xD800 <= x && x < 0xDC00 {
let high = x - 0xD800;
let low = match self.0.next() {
None => { return None; }
Some(v) => v
} - 0xDC00;
char::from_u32(0x10000 + (high << 10) + (low & 1023))
} else {
char::from_u32(x)
}
}
}
Отладка
Трассы стека по умолчанию, напечатанные при панике, слишком зашумлены. Обычно в нутро Rust наверху есть дюжина стековых фреймов, прежде чем он перейдет к важной части, пользовательскому коду, вызвавшему панику. Кроме того, здесь много визуального шума. Среди всех случайных шестнадцатеричных адресов трудно найти важную часть - номер файла и строки. Я бы хотел, чтобы Rust сделал то, что делает Python, и распечатал соответствующие фрагменты исходного кода в трассировке стека.
Еще одно раздражение заключается в том, что даже для режимов отладки компиляция занимает некоторое время (около 8 секунд для Enjarify), что является большим препятствием при отладке в цикле редактирование-> компиляция-> выполнение. Моим идеальным сценарием был бы интерпретатор, подобный Python, для отладки Rust, без компиляции, и хороший встроенный отладчик в стиле REPL и pdb (думаю, я предвзято, так как я так много использую Python). Индекс сломан
Типаж Index не работает, потому что он требует возврата ссылки на результат, ограничивая его коллекциями, которые фактически хранят соответствующий элемент. Вы не можете создавать и возвращать значения на лету. Это означает, что я не мог перегрузить [] для настраиваемого типа разреженного массива Enjarify и вынужден был довольствоваться get() и set() вместо этого. Это известная проблема, и я уже читал о ней перед началом перезаписи, поэтому я не стал терять время, пытаясь внедрить Index, но это все еще раздражает.
Вывод
Если у вас есть приложение Python и вы подумываете о его переписывании из-за шума статической типизации, вам следует серьезно пересмотреть свое решение, по крайней мере, если у вас больше тестов, чем разработчиков. Переписывание чего-либо занимает много времени и вызывает множество ошибок, переход от Python к менее выразительному языку означает повышенную нагрузку на обслуживание. Но если по какой-то причине вы все же хотите его переписать, не выбирайте Go. Rust лучше практически во всех отношениях.
Кроме того, я надеюсь, что мой опыт покажет пробелы, которые Rust все еще необходимо исправить.
Мнения, выраженные здесь, являются исключительно моими и не представляют моего работодателя или какую-либо другую организацию.