 Dudochkin Victor
Dudochkin Victor
Оптимизация использования памяти Rc в Rust
Перевод | Автор оригинала: Robert Grosse
Недавно я попытался оптимизировать код Rust с интенсивным использованием памяти. Это оказалось сложнее, чем я ожидал, но по пути я узнал кое-что интересное об использовании памяти Rust, поэтому пишу свою историю на случай, если кто-то еще сочтет ее полезной.
Основной алгоритм моего кода включает в себя манипулирование длинными строками, образованными путем многократной конкатенации друг с другом. Чтобы быть эффективными, строки должны быть неявно представлены в виде дерева (фактически, DAG) конкатенированных строк. Поэтому я определил структуру данных, чтобы представить их естественным образом:
enum LongStr {
Leaf(Vec<u8>),
Concat(RcStr, RcStr),
}
type RcStr = Arc<LongStr>;
Я использовал Arc, потому что мой код параллелен, но все последующее в равной степени применимо к Rc. В любом случае мой код создает миллиарды этих RcStr, которых достаточно, чтобы исчерпать даже 32 ГБ ОЗУ, поэтому важно сделать этот тип как можно меньше.
Сам по себе RcStr уже оптимален, так как это всего лишь указатель, а LongStr::Concat - всего лишь два указателя на подузлы. Однако есть один скрытый источник раздувания: слабый счетчик ссылок. Когда вы создаете Arc
struct ArcInner<T: ?Sized> {
strong: atomic::AtomicUsize,
weak: atomic::AtomicUsize,
data: T,
}
Однако на самом деле существует два счетчика ссылок. Второй нужен для поддержки слабых указателей, которые я не использовал. Следовательно, на каждый выделенный узел приходится 8 байтов потраченной впустую памяти, что является очевидной целью для оптимизации.
Я скопировал реализацию Arc из стандартных библиотек, исправил атрибуты импорта и крэйта до тех пор, пока он не скомпилировался, удалил счетчик слабых ссылок и все функции, связанные со слабыми указателями, и с нетерпением переписал код, чтобы сравнить использование памяти… и никаких изменений не было. Вот тогда все стало по-настоящему интересно / разочаровывающе.
Моя первая идея заключалась в том, что либо он не использовал мою модифицированную Arc, либо компилятор был достаточно гениальным, чтобы оптимизировать подсчет слабых ссылок. Поэтому я добавил неиспользуемое фиктивное поле [u8; 100] в мою копию ArcInner, и, конечно же, использование памяти резко возросло.
Затем я поэкспериментировал с изменением размера фиктивного поля, чтобы увидеть, как это влияет на использование памяти. Я установил его на 0, 16, 32 и 64 байта и получил ожидаемое линейное увеличение использования памяти.
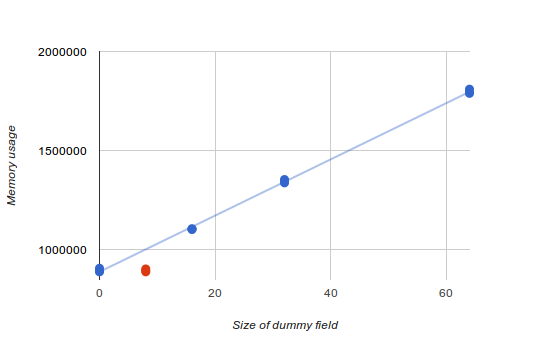
Однако, когда фиктивное поле было 8 байтов, имитируя удаленный счетчик слабых ссылок, использование памяти было таким же, как и с 0 байтами! (На графике выше это выделено красным). Это похоже на то, как боги оптимизации издевались надо мной, особенно пессимизируя один случай, который меня действительно волновал: 0 байтов против 8 байтов.
Моя следующая идея заключалась в том, что, возможно, возникла проблема с заполнением или выравниванием, из-за которой size_of
cargo rustc --release -- -Z print-type-sizes
Это дает следующий результат.
print-type-size type: `weakless::arc::ArcInner<LongStr>`: 40 bytes, alignment: 8 bytes
print-type-size field `.strong`: 8 bytes
print-type-size field `.dummy`: 0 bytes
print-type-size field `.data`: 32 bytesprint-type-size type: `weakless::arc::ArcInner<LongStr>`: 48 bytes, alignment: 8 bytes
print-type-size field `.strong`: 8 bytes
print-type-size field `.dummy`: 8 bytes
print-type-size field `.data`: 32 bytes
LongStr был 32 байта, больше, чем я ожидал, но я подумал, что беспокоюсь об этом позже. Важная часть заключается в том, что это показало, что не было никаких странных проблем с выравниванием или заполнением - ArcInner фактически переходит с 40 до 48 байтов, когда размер пустышки увеличивается с 0 до 8, как и ожидалось.
В конце концов я понял, что есть еще один возможный источник заполнения, который работает на более низком уровне, чем даже компилятор, - распределитель. Чтобы уменьшить фрагментацию, распределитель по умолчанию, jemalloc, группирует размеры небольших объектов в ячейки. Когда вы выделяете x байтов, на самом деле это не дает вам точно x байтов. Вместо этого он округляется до ближайшего размера корзины.
Я просмотрел размеры бункеров jemalloc, и, конечно же, есть бункер размером 48, но нет бина размером 40. Таким образом, выделение 40 и 48 байтов приводит к 48 байтам фактического использования памяти.
Фактически, список размеров ячеек от 16 до 128 - это [16, 32, 48, 64, 80, 96, 112, 128]. Это означает, что когда я изменил фиктивную переменную с 0 на 16, на 32, на 64 байта, размер структуры ArcInner увеличился с 40 до 56, до 72, до 104 байтов, что привело к использованию размеров ячеек 48, 64, 80 и 112. В каждом случае накладные расходы бункера были одинаковыми (8 байтов), так что мне повезло, что я получил красивый линейный паттерн.
К этому моменту я решил загадку, но мне все еще не удалось уменьшить использование памяти. К счастью, я заметил еще одну проблему. LongStr составлял 32 байта, что кажется больше, чем необходимо, поскольку узлы Concat содержат только два указателя (по 8 байтов каждый). Даже с 8-байтовым дискриминантом enum это составляет всего 24 байта.
Хитрость в том, что размер перечислений рассчитан на самый большой вариант, и в этом случае вариант Leaf был излишне большим. Он содержит Vec, который содержит указатель, поле длины и поле емкости, всего 24 байта, в результате чего перечисление составляет 32 байта. Однако в этом случае поле емкости совершенно бесполезно. Вы можете избавиться от него, переключившись с Vec
enum LongStr {
Leaf(Box<[u8]>),
Concat(RcStr, RcStr),
}
type RcStr = Arc<LongStr>;
Это сокращает LongStr до 24 байтов, что в сочетании с удалением счетчика слабых ссылок означает, что ArcInner
В любом случае, эта оптимизация оказалась намного сложнее, чем я ожидал, но я узнал много интересных деталей о Rust в процессе его отладки, и я надеюсь, что эта информация будет полезна другим.
Обновление: системный распределитель
Кто-то предложил мне попробовать использовать системный распределитель вместо jemalloc. Оказывается, это оказалось проще, чем я ожидал. Все, что вам нужно сделать, это положить его на верхнюю часть корня крэйта.
#![feature(alloc_system)]
extern crate alloc_system;
К сожалению, системный распределитель использовал значительно больше памяти, чем jemalloc, до такой степени, что он был настолько очевиден, что я не стал пытаться получить конкретные числа. Обратите внимание, что это со всеми упомянутыми выше оптимизациями, так как я мог не беспокоиться об их отмене, но если системный malloc не может обработать оптимизированный код, он определенно не сможет обработать исходную версию.
Обновление 2: режим безумия
Причина всех этих проблем с Arcs заключается в том, чтобы освободить память, когда на нее больше не ссылаются, но что, если вы просто намеренно все просочили и использовали &'static LongStr вместо Arc
fn leak_allocate<T>(val: T) -> &'static T {
let b: Box<_> = Box::new(val);
unsafe{&*Box::into_raw(b)}
}
Преимущество утечки памяти состоит в том, что вам больше не нужны все эти счетчики ссылок, уменьшая размер каждого узла до 24 байтов. Само по себе это не принесет пользы из-за проблемы с размером корзины. Однако единственная причина, по которой каждый ArcInner был выделен индивидуально, заключалась в том, чтобы их можно было отдельно освободить. Утечка памяти означает, что вы можете просто разместить все свои узлы непрерывно в гигантском списке массивов.
fn arena_allocate(val: LongStr) -> &'static LongStr {
thread_local! {
static ARENA: &'static TypedArena<LongStr> = leak_allocate(TypedArena::new());
}
ARENA.with(|ar| {
ar.alloc(val)
})
}
Очевидным недостатком утечки всей памяти является то, что вы используете память, что приводит к дополнительному разбиению на страницы. В моем случае у меня 32 ГБ ОЗУ и раздел подкачки 32 ГБ (на SSD). Теоретически, если на страницу последовательного LongStr больше не ссылаются, Linux должен заметить, что к ней нет доступа, и в конечном итоге вывести ее на страницу из памяти.
В любом случае, это интересная идея, но она оказалась медленнее, чем использование подсчета ссылок на практике, предположительно из-за всей дополнительной разбивки на страницы. Это также зависит от наличия достаточного пространства подкачки.
Обновление 3: битовая упаковка
Другой комментатор указал, что с небезопасным кодом можно полностью уйти до 16 байт. Хитрость в том, что на x64 указатели (пользовательского пространства) ограничены 47-битным адресным пространством. Это означает, что два указателя плюс дискриминант перечисления могут быть упакованы в 12 байтов, оставляя 4 байта для атомарного счетчика ссылок.
Я действительно пытался реализовать это, но он вылетел, и мне не хотелось отлаживать, почему. Я полагаю, что такова опасность написания умного небезопасного кода.