 Dudochkin Victor
Dudochkin Victor
Rust Performance: история о perf и flamegraph в Linux
Перевод | Автор оригинала: Adam Perry
Получение некоторого выигрыша в производительности в программе Rust с 7-строчным diff, с использованием cargo bench, perf и flamegraph в Linux.
Контекст
Я работаю над программой Rust, которая выполняет интенсивный анализ сотен гигабайт данных. На прошлой неделе я потратил пару дней, работая над улучшением производительности во время выполнения, и в конце концов наткнулся на стену. Уже существует несколько хороших сообщений в блогах о профилировании Rust, на которые я неоднократно ссылался в прошлом, но ни один из них полностью не охватывал то, что я хотел здесь сделать: использовать perf + flamegraph. Я слышал от нескольких людей, что perf - потрясающий инструмент (и это так!), А флеймографы выглядят круто и кажутся полезными.
Это долгая история обучения этому. Если вы еще не выполняли профилирование с помощью Rust, надеюсь, эта учетная запись может служить примером, когда вам нужно будет сделать это в следующий раз. Есть и некоторые не совсем интуитивные вещи, которые я обнаружил в ходе расследования.
Программа
Программа, над которой я работаю в $ DAY_JOB, выполняет анализ «метагеномных образцов» (последовательностей ДНК, собранных из смешанных биологических образцов). Он использует несколько структур данных, которые являются общими для приложений биоинформатики, и, к счастью, крэйт rust-bio уже выполняет здесь большую часть тяжелой работы (очевидный переход на будущее). Эта программа довольно быстрая, но еще недостаточно быстрая.
Тесты
Перед обязательным рекламным сообщением «Измерьте все», я думаю, было бы неискренним в сообщении о производительности не указывать на то, что автоматические тесты имеют неоценимое значение при внесении нефункциональных изменений. Если у вас есть набор тестов, которому вы можете доверять, чтобы убедиться, что ваши изменения верны, можно быстро перейти к улучшению производительности.
Измерение, измерение, измерение
Очевидно, что при работе над улучшением какой-либо метрики (например, времени выполнения) очень важно измерять влияние своих изменений. Особенно, если вы полагаетесь на оптимизирующие компиляторы, которые произошли от какого-то семейства непостоянных жутких зверей. Такие очевидные изменения, как «Я объединю эти две ветви в одну проверку» или «Я удалю проверку границ для этого доступа к массиву», могут показаться вам, чтобы убрать количество выполненных вычислений, но также могут в конечном итоге скрыть важную информацию. от оптимизатора, что отрицательно скажется на вашей общей производительности. Они также могут сделать вашу программу зловещей, поэтому, хотя я не эксперт, я уверен, что вы должны измерять все, что вы делаете, чтобы повлиять на производительность. И не используйте просто / usr / bin / time -v, хотя это только начало.
Я построил несколько базовых тестов для запуска с помощью ночного тестера Rust. Он выполняет некоторую статистическую работу, чтобы запустить тест достаточное количество раз, чтобы иметь хорошее представление о его фактическом времени выполнения, и легко предоставляет меру отклонений, с которыми он столкнулся при этом. В процессе написания этой статьи я заметил интересный пост в моем ленте в Твиттере о важности отслеживания доверительных интервалов при измерении результатов тестов. Это то, что в тестах Rust прилагается приличное усилие, хотя я обычно по-прежнему вызываю Cargo Bench несколько раз, чтобы убедиться, что все остается в пределах заявленного диапазона. К счастью, тестирование производительности в Rust не зависит от JIT или другой магии виртуальной машины, что значительно упрощает сбор стабильных результатов.
После того, как вы написали несколько тестов производительности (хорошее руководство см. В приведенной выше книге Rust, а в качестве примера приведен пример, который я написал для rust-bio), вам нужно запустить их, используя ночной компилятор, начиная с июля 2016 года. К счастью, Используя rustup, очень легко использовать ночной компилятор для запуска тестов (или clippy), при этом используя стабильный компилятор для повседневной разработки:
$ rustup run nightly cargo bench
... cargo builds your dependencies
... cargo builds your benchmarks
...
...
... cargo is still building your benchmarks
...
... cargo starts running your benchmarks
... cargo skips some non-benchmark tests
Running target/release/distance-76e9e0fb6e8adddc
running 5 tests
test bench_hamming_dist_equal_str_1000iter ... bench: 3,042,154 ns/iter (+/- 102,699)
... and so on
test result: ok. 0 passed; 0 failed; 0 ignored; 5 measured
Та-да!
Как я уже сказал, когда я впервые начал работать над улучшением времени выполнения этой программы, я написал пару небольших тестов, и все шло отлично. Я бы внес изменения, запустил тесты, подождал 20-30 минут и посмотрел, повысились или снизились некоторые цифры. Фантастика! Я добился большого прогресса в этом.
Удар об стену - становится лучше
Затем произошло несколько проблем. Во-первых, 20-30 минут - это очень долгий срок, чтобы выяснить, оказал ли ваш 5-байтовый diff существенное влияние на производительность вашей программы. Во-вторых, у меня закончились очевидные изменения. Что делать после того, как вы полностью исключили вызовы clone(), выполнили все мыслимые параллельно, удалили все несущественные проверки и вычисления? Что ж, разберись, на что тратится время. Это относительно просто, если вы можете просто отметить записи журнала и выполнить небольшое «профилирование printf». Не так просто обрабатывать миллионы входных данных, каждый из которых обрабатывается за достаточно короткое время, так что временные метки регистрации не будут иметь значения.
Затем я настроил свои тесты производительности для работы с perf и flamegraph, чтобы я мог выяснить, на что тратилось больше всего времени, и впоследствии построить более быстрый, но все же полезный тест только для этих функций.
Настройка Rust
Если вы следили за моими спорадическими псевдо-примерами, у вас, вероятно, установлен rustup и загружен ночной Rust, и, вероятно, у вас также есть некоторые тесты, написанные для работы с тестовым жгутом Rust. Как упоминалось выше, вам также понадобятся символы отладки в ваших двоичных файлах, если вы хотите использовать perf. Обычный способ сделать это (опуская флаг --release в вашей сборке) не будет работать по двум причинам:
- Обычно мы заботимся о профиле производительности оптимизированных двоичных файлов.
- Cargo bench создает ваш проект с включенным флагом --release за кулисами.
Итак, временно добавьте это в свой Cargo.toml или измените существующий профиль выпуска:
[profile.release]
debug = true
Вам также может потребоваться добавить lto = false в ваш профиль выпуска. Я столкнулся с несколькими проблемами при попытке использовать LTO одновременно с включенными отладочными символами.
perf
perf - отличный инструмент для профилирования процесса Linux на основе выборки. В вики есть хороший учебник, и Брендан Грегг также подготовил несколько очень хороших учебных материалов. Если вы здесь, чтобы узнать, как использовать perf с Rust, вы можете выполнить следующие основные шаги, а затем перейти по этим ссылкам, чтобы узнать, как это действительно сделать для ваших (возможно, более продвинутых) вариантов использования.
В основном, мое использование perf включает:
- Запуск моей программы с использованием записи perf, чтобы проверить ее выполнение.
- Анализ результатов с использованием комбинации диаграмм пламени, отчета о производительности и аннотации производительности.
Есть множество других отличных вещей, которые может выполнять perf, например, отслеживание определенных событий ядра, подсчет попаданий / промахов в кеш и другая статистика, профилирование поведения JIT (например, в JVM или V8) и, возможно, другие. Однако, исходя из моего ограниченного опыта, большую часть времени, если вы выполняете профилирование ЦП, вам просто нужно понять, на что тратится время и почему.
Фламеграфы
График пламени - это действительно хороший визуальный способ представить процессорное время (или другие ресурсы) программы. Если вы следите за мной, я предполагаю, что вы установили perf, а также разместили скрипты flamegraph где-нибудь в своем PATH.
Допустим, вы хотите быстро визуализировать, где программа проводит время. Скажем, эта программа представляет собой тестовый тест Rust с гипотетическим названием magic_bench и что она содержит функцию magic_bench, которая вас интересует. Вы можете запустить такие команды:
Создайте исполняемый файл нашего теста, не запуская его:
$ cargo bench --no-run
Запустите его через perf и запустите только тот тест, который нас интересует (обязательно включите параметр -g, который включает запись графика вызовов - обязательное условие для flamegraph):
$ perf record -g target/release/magic_bench-* --bench magic
Построим флеймеграф всей программы:
$ perf script | stackcollapse-perf | flamegraph > flame.svg
Если мы откроем flame.svg, мы увидим очень удобную визуализацию времени процессора, затрачиваемого на различные вызовы функций. Горизонтальное пространство соответствует проценту времени выполнения родителя, потраченного на данную функцию.
Однако в моем конкретном случае эталонный тест должен был инициализировать очень дорогостоящий индекс, прежде чем он сможет выполнить любой из запросов эталонного теста, и это заняло примерно 98% времени выполнения эталонного теста, уменьшая полезность всего программного флеймографа. .
Отличная часть скриптов stackcollapse для flamegraph заключается в том, что они позволяют искать функции, соответствующие шаблону. Совет: все жгуты тестов Rust вызывают закрытие, например, так: bencher.iter (|| do_measured_thing()), легко позволяя вам использовать grep для вызовов закрытий, чтобы ограничить флеймограф в основном внутренним, неинициализационным циклом вашего теста:
$ perf script | stackcollapse-perf | grep closure | flamegraph > flame.svg
Это дает такой флеймеграф, где цикл теста сам по себе является главной достопримечательностью:

Забавная история: видите ли вы две коробки во втором сверху ряду, которые даже не достаточно велики, чтобы на них можно было разместить ярлыки? Да, вот где я потратил около дня на улучшение, прежде чем я начал углубленное профилирование. Измеряйте, измеряйте, измеряйте.
Увеличение времени выполнения работ
Итак, я обнаружил, что подавляющее большинство времени, которое я трачу на запросы к этим структурам данных, заканчивается вызовом библиотеки: bio::data_structures::bwt::Occ::get. Если я смогу написать быстрый тест для этой функции (и друзей), я, вероятно, смогу немного быстрее повторить и попробовать различные улучшения. Так я и сделал!
И вот график закрытия этого теста, просто чтобы подтвердить, что его профилирование несколько похоже на гораздо более длительный тест из моего приложения:
$ cd ~/rust-projects/rust-bio
$ cargo bench --no-run && \
perf record -g target/release/fmindex-* --bench seed && \
perf script | stackcollapse-perf | grep closure | flamegraph > flame.svg
В результате чего:

Погружение глубже
С помощью приведенной выше команды мы сгенерировали флеймеграф, но в процессе perf также сохранил большой файл данных honkin, который мы можем использовать для дальнейшего анализа без повторного запуска наших тестов. У perf есть несколько хороших обозревателей TUI и GUI для профилирования данных, поэтому, например, мы можем запустить отчет perf, чтобы получить иерархию профилированных функций с возможностью навигации с клавиатуры:
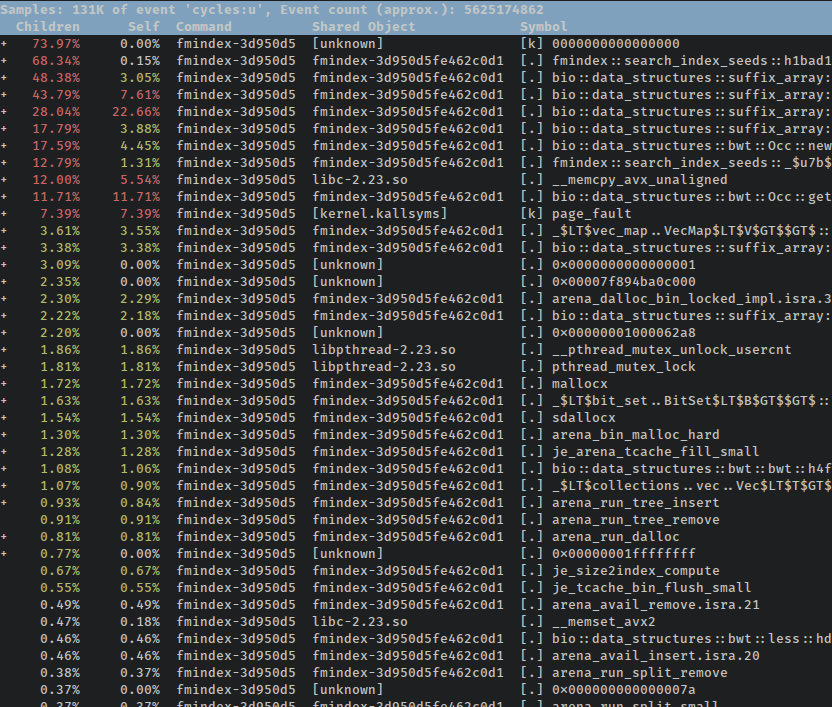
В этом конкретном случае мы снова сталкиваемся с проблемой, когда сам тест теряется в коде, который инициализирует индексы. Есть очень удобный флаг --symbol-filter $ FILTER, который вы можете передать в отчет о перфомансе, чтобы получить тот же эффект, что и при поиске свернутых стеков для графа пламени:
$ perf report --symbol-filter closure
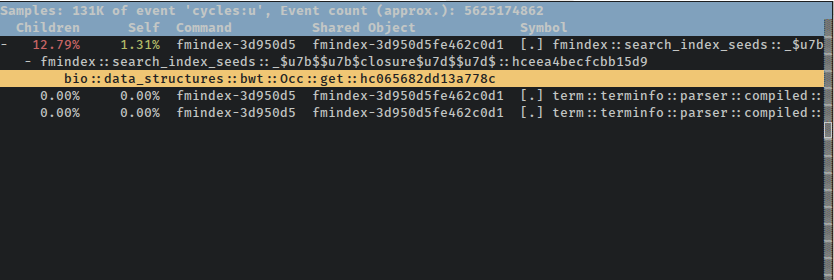
perf также позволяет просматривать аннотированный исходный код с помощью команды perf annotate. Однако, если мы хотим ограничить вывод этой команды одним вызовом функции и ее дочерними элементами, мы должны знать точный символ, AFAIK. Флаг --symbol-filter для передачи аннотации отсутствует, но если вы нажмете Enter, когда нужная функция выделена в TUI отчета, он позволит вам выбрать открытие аннотированного источника только для этой функции:
Самая горячая петля в стране
Прежде чем перейти к аннотированному исходному тексту и дизассемблированию этой функции: flamegraph показал, что большая часть времени тестирования тратится на bio::data_structures::bwt::Occ::get. В rust-bio этот тип и его метод являются частью реализации индекса FM. Это супер классная структура данных, которая позволяет выполнять очень эффективный поиск точных совпадений строки поиска в смехотворно больших текстах. Это достигается путем объединения некоторых очень интересных свойств нескольких различных индексов, один из которых является выборочным подсчетом появления символов в преобразовании Барроуза-Уиллера (подсказка: он также включает в себя некоторую темную магию и кровные пакты). Именно эта структура выборки данных (названная Occ в rust-bio) запрашивается для получения частоты появления байта до заданной точки в BWT.
Вот функция, о которой идет речь, как она присутствует в rust-bio:
pub fn get(&self, bwt: &BWTSlice, r: usize, a: u8) -> usize {
// self.k is our sampling rate, so find our last sampled checkpoint
let i = r / self.k;
// count all the matching bytes b/t the closest checkpoint and our desired lookup
// return the sampled checkpoint for this character + the manual count we just did
self.occ[i][a as usize] +
bwt[(i * self.k) + 1 .. r + 1].iter()
.map(|&c| (c == a) as usize).fold(0, |s, e| s + e)
}
Он извлекает отсчет выборки до этой точки, а затем подсчитывает любые совпадающие символы в BWT от точки выборки до точки нашего поиска. Вот базовая производительность этой версии функции в тесте, который я написал для проверки производительности этих поисков FM Index:
$ cargo bench search
...
Running target/release/fmindex-3d950d5fe462c0d1
running 1 test
test search_index_seeds ... bench: 52,239 ns/iter (+/- 403)
Стоит отметить, что эта среда выполнения предназначена для полного поиска по индексу, а не только для выполнения функции Occ::get. Тест выполняет поиск местоположений для нескольких строк поиска, и индекс FM может вызывать Occ::get много раз для каждого из этих поисков.
Вот небольшая часть исходного кода этой функции с аннотациями, как и было обещано. Вы можете видеть, что perf отображает процентное значение в левом столбце (% от общего числа выборок для этого символа), выделяет общие инструкции зеленым, выделяет горячие инструкции красным, а также чередует исходный источник с соответствующей сборкой, где это возможно:
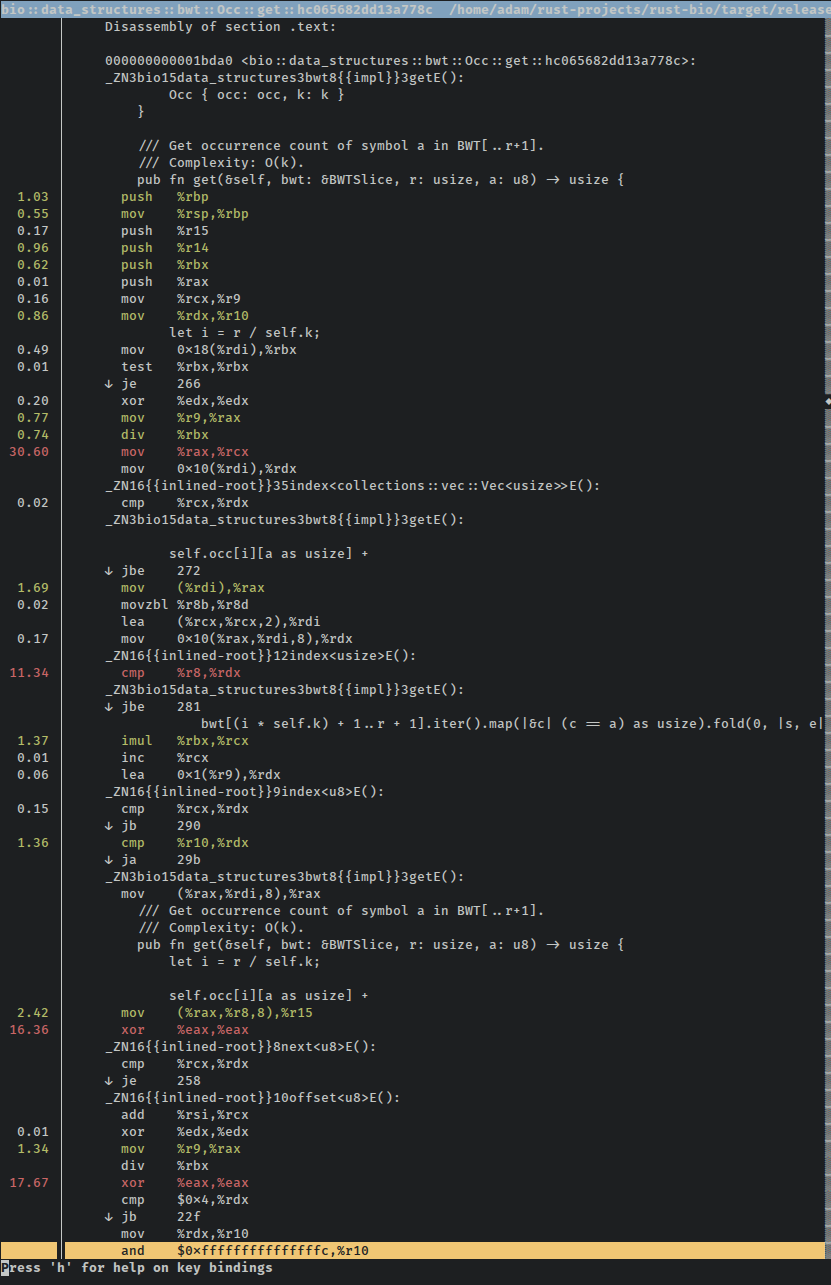
Подождите, «небольшая часть»? Да, есть несколько экранов сборки для того, что по сути является поиском в 2D-массиве, за которым следует цикл подсчета по части другого массива. Что-то пошло не так!
Все (включая меня) говорят мне, что итераторы Rust - это волшебство, и что в сочетании с магией LLVM все должно быть мономорфизировано, свернуто константой, встроено и поднято петлей и ... Я вообще-то не знаю, как работают оптимизации компилятора. Но общее мнение таково, что использование итераторов часто дает LLVM более чем достаточно информации о рассматриваемых циклах для создания кричащего быстрого кода, основанного на хороших высокоуровневых абстракциях. И хотя я могу показаться немного саркастичным по этому поводу, я лично измерил по крайней мере полдюжины горячих петель, в которых адаптеры итераторов Rust превосходят мои созданные вручную петли. Конечно, я не большой любитель петель, но меня это всегда впечатляло.
Идиоматичность (Идиоматичность? Идиоматичность?)
Прежде чем избыток оптимизированной сборки заставит нас бежать из страха перед адаптерами итераторов, возможно, есть способ получше. Во-первых, отображение логического значения как целого числа и сворачивание его в аккумуляторную переменную - это несколько своеобразный способ подсчета количества элементов в срезе, которые соответствуют предикату. Возможно, Rust / LLVM просто выражает свое недоумение единственным известным ему способом? Может быть, немного более идиоматичный набор адаптеров итераторов был бы более приемлемым и удовлетворил бы божества сверхъестественной оптимизации? Как насчет фильтра и счетчика?
pub fn get(&self, bwt: &BWTSlice, r: usize, a: u8) -> usize {
// self.k is our sampling rate, so find our last sampled checkpoint
let i = r / self.k;
// count all the matching bytes b/t the closest checkpoint and our desired lookup
let count = bwt[(i * self.k) + 1 .. r + 1].iter().filter(|&&c| c == a).count();
// return the sampled checkpoint for this character + the manual count we just did
self.occ[i][a as usize] + count
}
Результаты:
$ cargo bench search
...
Running target/release/fmindex-3d950d5fe462c0d1
running 1 test
test search_index_seeds ... bench: 34,485 ns/iter (+/- 947)
Поскольку я слишком многословен, чтобы вы могли легко увидеть цифры из исходной версии, я отмечу, что, по моим подсчетам, это увеличение скорости на ~ 34% по сравнению с предыдущей версией, и это улучшение, выходящее далеко за рамки сообщенных полос ошибок. с помощью тестовой системы Rust.
Ура! Если мы снова запустим тест через запись perf, мы сможем запустить разборку и посмотреть, что изменилось. Разборка намного меньше, и нет никаких запутывающих блоков из многих повторяющихся инструкций. Это вся функция (исключая обработчики паники только на снимке экрана):
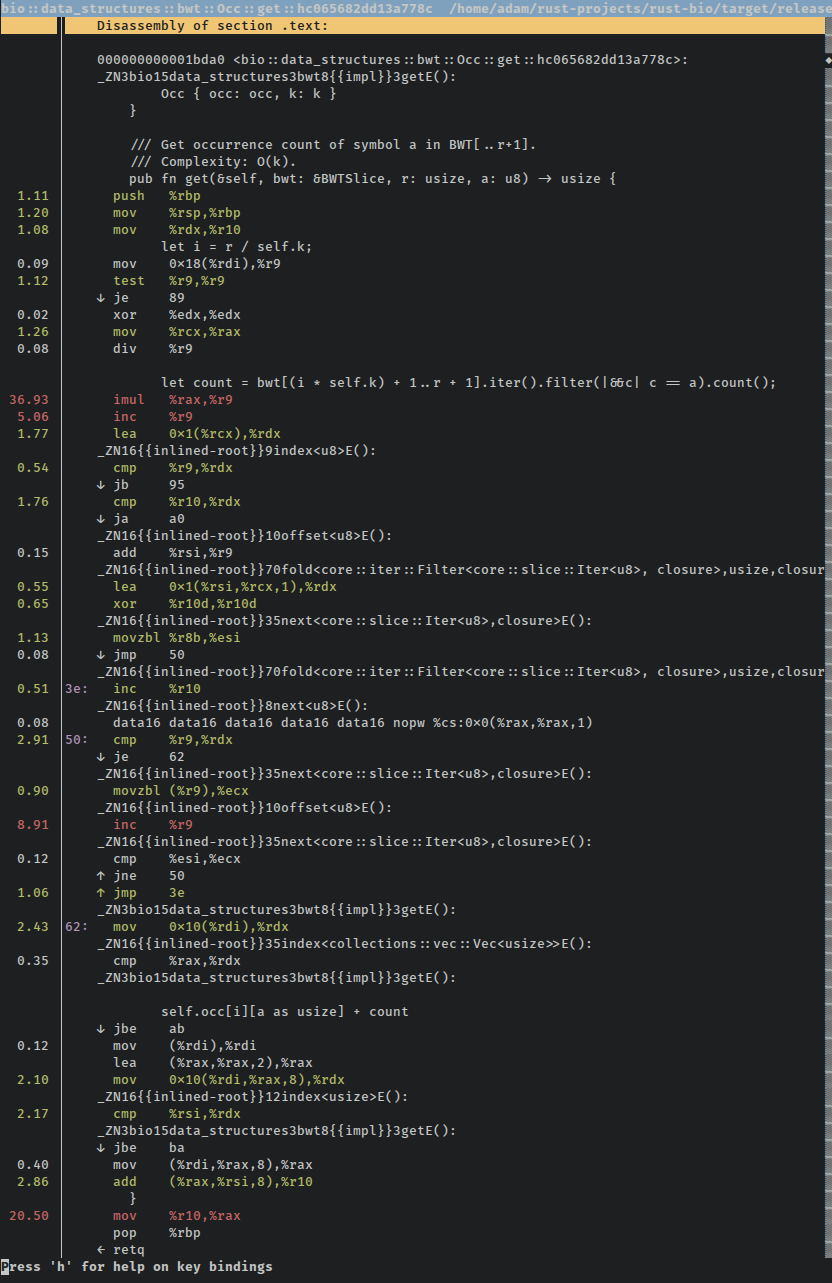
Возможность разместить всю функцию на одном экране - хороший знак, не так ли? Наши тесты все еще проходят, производительность повышается, и для тех же функций используется гораздо меньше инструкций, что является хорошим трэйтом того, что ранее не вызываемые оптимизации ворвались в мир смертных, чтобы насладиться самой сутью нашей программы.
Сделай сам
Может, мы сможем сделать это еще быстрее? Это очень горячая петля, и любые победы здесь пойдут на пользу. Оптимизация итератора в Rust обычно довольно хороша, но, возможно, оптимизатору будет легче справиться с ручным подсчетом элементов. Как насчет старой доброй мутации переменной счетчика?
pub fn get(&self, bwt: &BWTSlice, r: usize, a: u8) -> usize {
// self.k is our sampling rate, so find our last sampled checkpoint
let i = r / self.k;
let mut count = 0;
// count all the matching bytes b/t the closest checkpoint and our desired lookup
for idx in (i * self.k) + 1 .. r + 1 {
if bwt[idx] == a {
count += 1;
}
}
// return the sampled checkpoint for this character + the manual count we just did
self.occ[i][a as usize] + count
}
Результаты:
$ cargo bench search
...
Running target/release/fmindex-3d950d5fe462c0d1
running 1 test
test search_index_seeds ... bench: 35,309 ns/iter (+/- 327)
Разница находится в пределах шкалы ошибок как для «идиоматических итераторов», так и для этой «хипстерской» версии. Однако несколько последовательных прогонов подтверждают, что эти средние значения достаточно стабильны. Так что, хотя на некоторых запусках это может быть быстрее, чем предыдущая версия, кажется, что в целом это, вероятно, немного медленнее. Глядя на самый верх этого снимка экрана с разборкой, можно увидеть, что несколько процентов количества инструкций, похоже, тратятся на сравнения, которые предназначены для переходов к границам, проверяют обработчики паники (perf - это круто):
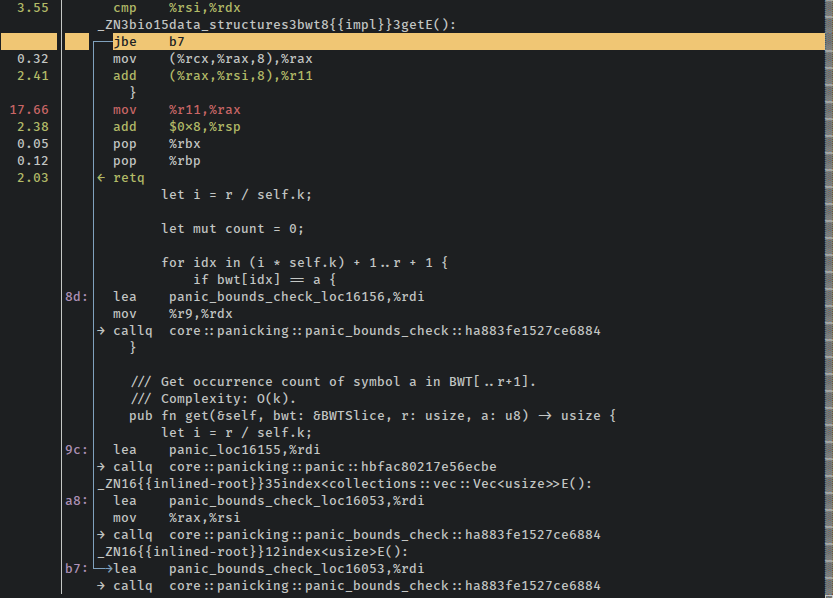
Страшные границы снова проверяют удары. Это избавляет нас от считывания концов Vecs, которые составляют эти индексы, но это также стоит нам циклов.
Это такой (голый) металл
Что, если мы будем использовать небезопасное индексирование? Из построения Vecs и из множества тестов мы знаем, что мы вряд ли выйдем за границы, и если производительность будет достаточно хорошей, мы всегда можем вернуться и добавить assert в начало функции. Может быть, если мы воспользуемся каким-нибудь разумным небезопасным способом пропустить проверки границ, мы сократим эти несколько процентов?
pub fn get(&self, bwt: &BWTSlice, r: usize, a: u8) -> usize {
// self.k is our sampling rate, so find our last sampled checkpoint
let i = r / self.k;
let mut count = 0;
// count all the matching bytes b/t the closest checkpoint and our desired lookup
for idx in (i * self.k) + 1 .. r + 1 {
unsafe {
if *bwt.get_unchecked(idx) == a {
count += 1;
}
}
}
// return the sampled checkpoint for this character + the manual count we just did
unsafe {
self.occ.get_unchecked(i).get_unchecked(a as usize) + count
}
}
Результаты:
$ cargo bench search
...
Running target/release/fmindex-3d950d5fe462c0d1
running 1 test
test search_index_seeds ... bench: 46,067 ns/iter (+/- 238)
Это... намного хуже, чем любое из внесенных нами улучшений, и определенно выходит за пределы допустимой погрешности этих тестов.
Святая корова! Что случилось? Похоже, оптимизатор здесь не слишком перегружен. Дизассемблирование содержит множество инструкций, которые не были необходимыми или полезными в безопасной версии этой функции, и выглядят очень похоже на исходную версию, только без вызовов функций итератора:
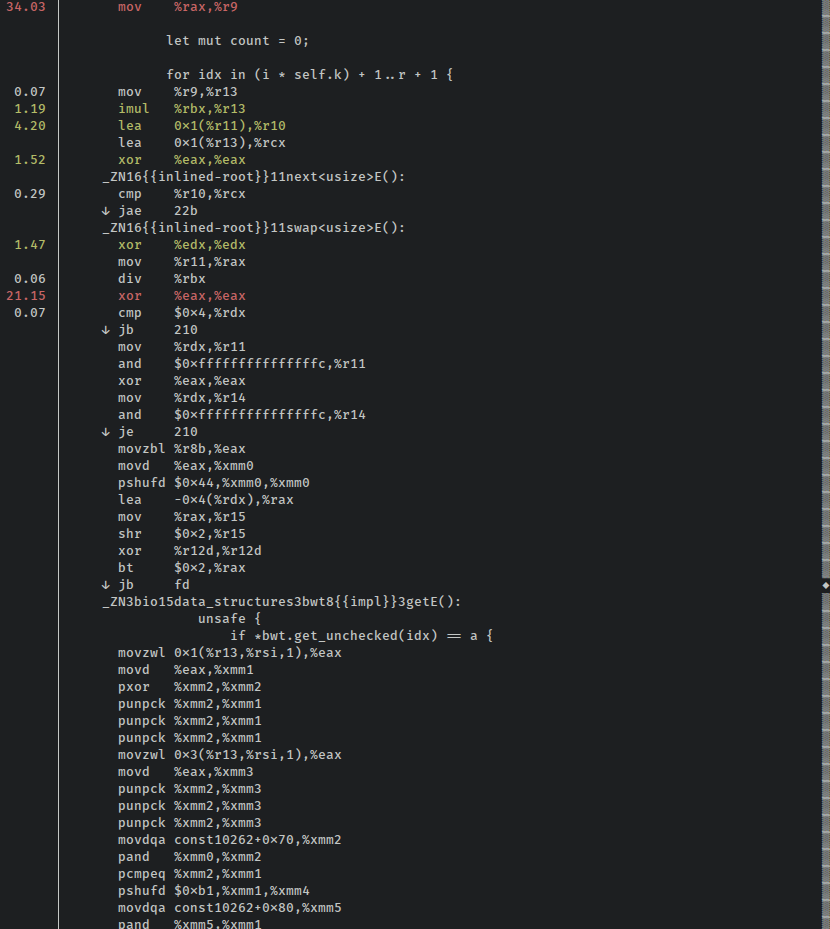
Важное примечание: всякий раз, когда кто-то вроде меня защищает Rust и говорит вам, что вы «всегда можете удалить проверки границ в горячих циклах», напоминайте им, что в некоторых случаях это может не помочь. Я не искал исчерпывающим образом в системе отслеживания проблем Rust, чтобы увидеть, является ли это ошибкой, так что, возможно, она уже устраняется. Тем не менее, удаление проверок границ не является большой красной волшебной кнопкой «сделать быстрее», и, как я, возможно, уже упоминал, вам абсолютно необходимо измерить влияние на производительность «очевидных» изменений.
Также интересно, когда я пробую версию индексации с проверкой границ в своей более крупной программе, она иногда работает на несколько процентов лучше, чем пример идиоматического итератора! Поймите, ритуалы призыва для оптимизации загадочны и полны нюансов и опасностей. Версия с непроверенным индексированием все еще там неэффективна, и я подозреваю, что Rust, вероятно, мог бы лучше выводить LLVM IR без проверки границ, или регистрировать разные проходы LLVM или что-то в этом роде, но я не эксперт здесь, это даже отдаленно не смешно.
Запрос на включение
Открытый исходный код - это фантастика! Мне не только не нужно было писать все эти структуры данных самому, но я также могу делиться своими улучшениями с кем-либо еще, кто их использует. Запрос на вытягивание был объединен, и в ближайшее время улучшение производительности должно быть доступно на crates.io.
Хотя для моего варианта использования производительность иногда немного лучше при использовании версии с индексированием с проверкой границ (в отличие от адаптеров итераторов), поскольку у меня нет доказательств того, что это было бы полезно для других приложений, которых я не делал. думаю, что это будет разумно для апстрима.
Прощальные мысли
Инструменты для профилирования - это круто! Это было бы гораздо труднее исследовать без сложных инструментов. Во-первых, было бы невозможно просто обнаружить, что функция Occ::get отнимает так много времени. Более того, детальное рассмотрение последствий внесенных в него изменений было бы в лучшем случае затруднительным. Наконец, понимание природы замедления / ускорения имеет неоценимое значение для будущих усилий по оптимизации.
Производительность сгенерированного кода всегда будет немного изменяться. И сейчас много внимания уделяется производительности компилятора, но, как ни странно, еще не предпринимается никаких попыток систематически отслеживать производительность скомпилированных программ на Rust. Я пробовал это раньше и не очень далеко продвинулся, есть ярлык I-slow для проблем, которым уделяется много внимания (так что откройте его, если вы обнаружите плохой кодогенератор), а также проблема отслеживания для создания набор регрессионных тестов perf, который может прогрессировать или не прогрессировать.
Мне сказали, что всякий раз, когда MIR включается по умолчанию, он позволяет выполнять новые оптимизации в интерфейсе Rust до того, как будет сгенерирован любой IR LLVM. Это может радикально изменить то, какой вид ручной оптимизации оказывает влияние. Я попытался запустить эти тесты с RUSTFLAGS = "- Z orbit" и не увидел разницы. Предполагая, что я использовал правильный флаг (ха!), MIR trans ведет себя аналогично генерации кода по умолчанию для этого случая ... пока.
Я полностью забыл включить измерения или снимки экрана, но когда я попытался вручную выполнить итерацию по срезу (без использования адаптеров итератора, но и без ручного индексирования), я не добился значительного повышения производительности по сравнению с версией, проиндексированной вручную, показанной здесь. Это, безусловно, требует дальнейшего изучения. (похоже, что это, вероятно, из-за некачественной векторизации, см. Обновление ниже)
Если вы пишете код, критичный к производительности, отнеситесь к этому с недоверием, когда Rustaceans скажет вам, что Vec::get_unchecked должен улучшить производительность. Очевидно, это правда во многих случаях (включая те, над которыми я недавно работал), но измерять, измерять ... ох, я устал писать это.
Обновление (25.07.16)
Что касается /r/rust, /u/Aatch провел очень глубокий анализ результатов сборки (за пределами моего понимания) и пришел к очень интересным выводам. По сути, удаление проверок границ фактически позволяет векторизовать цикл, и именно версия SIMD работает намного медленнее.
Я упустил тот факт, что в примерах документации, которые я скопировал для теста, я использовал очень низкое значение k в Occ. Поэтому, когда LLVM смог векторизовать функцию, векторизованная версия всегда вызывалась на входах, слишком маленьких, чтобы воспользоваться преимуществами векторизованных сумм при ручном подсчете BWT.
Это было бы интересной странностью (разве не безумие, что оптимизации сделали это намного медленнее?), За исключением того факта, что k = 3 намного ниже, чем типичное использование в реальном мире, AFAICT. Одно приложение C++, которое я часто вижу, использовало значения по умолчанию для k = 32, и я возился с компромиссами с гораздо более высокими частотами дискретизации, такими как 128 или 256. Оказывается, векторизованная версия работает ужасно быстро (даже с безопасным кодом), как только вы частота дискретизации выше 32. Я открыл PR, чтобы обсудить эти компромиссы.
Я не думаю, что это изменит полезность демонстрации того, как использовать эти инструменты с Rust, но это определенно бросает мне вызов! И это определенно подчеркивает важность разумного измерения и двойной проверки своих предположений!
Обратная связь?
Большое спасибо pczarn и краткости в # rust-offtopic за то, что вы нашли время прочитать это и предоставили очень полезные правки.
Контактные ссылки находятся в нижнем колонтитуле. Обычно я нахожусь в #rust на irc.mozilla.org как anp.
Я также разместил это в Hacker News и в сабреддите /r/rust, если вы хотите обсудить это в любом из этих мест.
РЕДАКТИРОВАТЬ: Моя публикация в HN действительно никуда не делась, но похоже, что она была повторно отправлена.