 Dudochkin Victor
Dudochkin Victor
6. Получение твитов из программы
Перевод | Автор оригинала: Loris
ЭПИЗОД 6
2 МЕСЯЦА НАЗАД
ЧТЕНИЕ 8 МИН.
Давайте посмотрим, что мы уже узнали. Внедрение программы Solana, которая создает учетные записи Tweet... Проверьте! ✅ Взаимодействие с нашей программой из клиента для отправки твитов в блокчейн... Проверка! ✅ Получение всех наших твитов, чтобы показать их нашим пользователям... Хм... Нет! ❌
Давайте научимся это делать прямо сейчас! Мы добавим несколько тестов, которые извлекают несколько твитов и гарантируют, что мы получим правильные твиты в нужном количестве.
Получение всех твитов
Давайте начнем с простого, извлекая все учетные записи Tweet, когда-либо созданные в блокчейне.
В предыдущем эпизоде мы узнали, что Anchor предоставляет небольшой API для каждого типа учетной записи внутри объекта program. Например, чтобы получить API учетной записи Tweet нам нужно получить доступ к «program.account.tweet».
Ранее мы использовали метод fetch внутри этого API для получения конкретной учетной записи на основе ее открытого ключа. Теперь воспользуемся другим методом all, который просто возвращает их все!
const tweetAccounts = await program.account.tweet.all();
Точно так же у нас есть массив всех когда-либо созданных учетных записей твитов.
Давайте добавим новый тест в конец файла tests/solana-twitter.ts. Мы добавляем его в конце, потому что нам нужно убедиться, что у нас есть учетные записи для извлечения. Первые 5 тестов завершаются созданием 3 учетных записей твитов — так как 2 теста убедитесь, что учетные записи не создаются при определенных условиях.
Поэтому наш новый тест извлечет все учетные записи и убедится, что у нас их ровно 3.
it('can fetch all tweets', async () => {
const tweetAccounts = await program.account.tweet.all();
assert.equal(tweetAccounts.length, 3);
});
Теперь, если мы запустим anchor test, мы должны увидеть, что все 6 тестов пройдены!
Обратите внимание, что для того, чтобы этот новый тест всегда работал, нам нужно убедиться, что наша локальная книга пуста, прежде чем запускать тесты. При запуске «теста привязки» Anchor делает это автоматически, запуская новую пустую локальную книгу.
Однако, если вы запускаете тесты со своим собственным локальным реестром — запустив «solana-test-validator» и «anchor run test» в другом сеансе терминала, — обязательно сбросьте локальный реестр перед запуском тестов, выйдя из текущего локального реестра. леджер и начать новую пустую, используя solana-test-validator --reset. Если вы этого не сделаете, то при следующем запуске тестов у вас будет 6 твит-аккаунтов, и поэтому наш новый тест не пройдет.
Это относится к пользователям Apple M1, которые должны запускать solana-test-validator --no-bpf-jit --reset и anchor test --skip-local-validator вместо anchor test. Просто убедитесь, что вы перезапускаете локальный реестр перед каждым запуском тестов.
Фильтрация твитов по автору
Хорошо, давайте перейдем к нашему следующему тесту. мы знаем, как получить все когда-либо созданные учетные записи Tweet, но как мы можем получить все учетные записи, соответствующие определенным критериям? Например, как мы можем получить все учетные записи Tweet от определенного автора?
Оказывается, вы можете предоставить массив фильтров для метода all() выше, чтобы сузить область вашего результата.
Solana поддерживает только 2 типа фильтров, и оба они довольно примитивны.
Фильтр dataSize
Первый фильтр, называемый dataSize, довольно прост. Вы указываете ему размер в байтах, и он будет возвращать только те учетные записи, которые точно соответствуют этому размеру.
Например, таким образом мы можем создать фильтр dataSize размером 2000 байт.
{
dataSize: 2000,
}
Все, что больше или меньше 2000 байт, не будет включено в результат.
Поскольку все наши учетные записи Tweet имеют размер 1376 байт, это не очень полезно для нас.
Фильтр memcmp
Второй фильтр, называемый memcmp, немного полезнее. Это позволяет нам сравнивать массив байтов с данными аккаунта по определенному смещению.
Это означает, что нам нужно предоставить массив байтов, которые должны присутствовать в данных учетной записи в определенной позиции, и он будет возвращать только эти учетные записи.
Итак, нам нужно предоставить 2 вещи:
offset: позиция (в байтах), с которой мы должны начать сравнение данных. Это ожидает целое число.- Массив
bytes: данные для сравнения с данными учетной записи. Этот массив байтов должен быть закодирован в базе 58.
Например, предположим, что я хотел получить все учетные записи, у которых мой открытый ключ находится на 42-м байте. Затем я мог бы использовать следующий фильтр memcmp.
{
memcmp: {
offset: 42, // Starting from the 42nd byte.
bytes: 'B1AfN7AgpMyctfFbjmvRAvE1yziZFDb9XCwydBjJwtRN', // My base-58 encoded public key.
}
}
Обратите внимание, что фильтры memcmp сравнивают только точные данные. Мы не можем, например, проверить, что целое число в определенной позиции меньше заданного числа. Тем не менее, этот фильтр memcmp достаточно мощный, чтобы мы могли использовать его в нашем твиттер-подобном dApp.
Используйте фильтр memcmp для открытого ключа автора.
Ладно, вернемся к делу. Давайте используем этот фильтр memcmp для фильтрации твитов от данного автора.
Итак, нам нужны две вещи: offset и bytes. Для смещения нам нужно узнать, где в данных хранится публичный ключ автора. К счастью, мы уже сделали всю эту работу в третьем эпизоде.
Мы знаем, что первые 8 байтов зарезервированы для дискриминатора, а затем следует открытый ключ автора. Поэтому наше смещение просто: 8.

Теперь для bytes нам нужно предоставить открытый ключ в кодировке base-58. В целях нашего теста мы будем использовать открытый ключ нашего кошелька для получения всех твитов, опубликованных кошельком.
В итоге мы получаем следующий фрагмент кода.
const authorPublicKey = program.provider.wallet.publicKey
const tweetAccounts = await program.account.tweet.all([
{
memcmp: {
offset: 8, // Discriminator.
bytes: authorPublicKey.toBase58(),
}
}
]);
Учитывая, что только две из трех учетных записей Tweet, созданных в тестах, относятся к нашему кошельку, переменная tweetAccounts должна содержать только две учетные записи.
Давайте поместим этот код в новый тест и убедимся, что мы вернем ровно две учетные записи.
it('can filter tweets by author', async () => {
const authorPublicKey = program.provider.wallet.publicKey
const tweetAccounts = await program.account.tweet.all([
{
memcmp: {
offset: 8, // Discriminator.
bytes: authorPublicKey.toBase58(),
}
}
]);
assert.equal(tweetAccounts.length, 2);
});
Давайте будем немного более строгими в этом тесте и убедимся, что обе учетные записи внутри tweetAccounts действительно принадлежат нашему кошельку.
Для этого мы пройдемся по массиву tweetAccounts, используя функцию every который возвращает true тогда и только тогда, когда предоставленный обратный вызов возвращает true для каждой учетной записи.
it('can filter tweets by author', async () => {
const authorPublicKey = program.provider.wallet.publicKey
const tweetAccounts = await program.account.tweet.all([
{
memcmp: {
offset: 8, // Discriminator.
bytes: authorPublicKey.toBase58(),
}
}
]);
assert.equal(tweetAccounts.length, 2);
assert.ok(tweetAccounts.every(tweetAccount => {
return tweetAccount.account.author.toBase58() === authorPublicKey.toBase58()
}))
});
Готово! У нас есть второй тест, и мы умеем фильтровать по авторам! 🎉
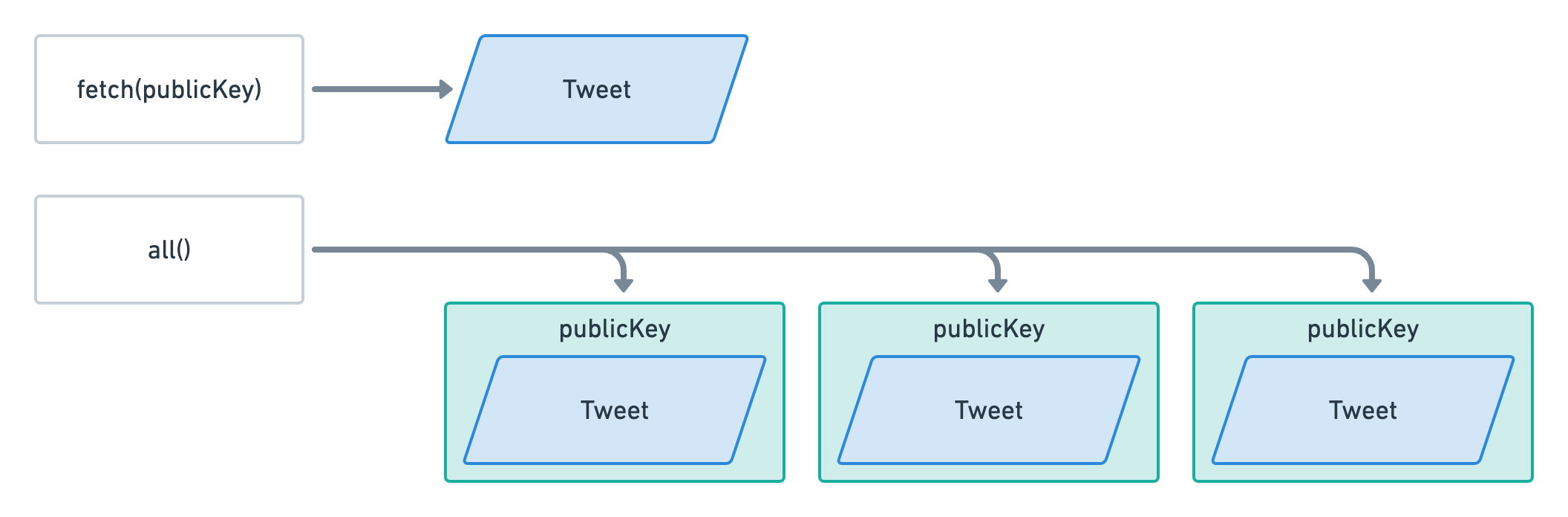
Вам может быть интересно, почему мы получаем доступ к открытому ключу автора через tweetAccount.account.author, тогда как при использовании метода fetch мы обращались к нему напрямую через tweetAccount.author. Это потому, что методы fetch и all не возвращают одни и те же объекты.
При использовании fetch мы получаем учетную запись Tweet со всеми проанализированными данными.
При использовании all мы получаем тот же объект, но внутри объекта-оболочки, который также предоставляет свой publicKey. При использовании fetch мы уже предоставляем открытый ключ учетной записи, поэтому этому методу не обязательно возвращать его. Однако при использовании all мы не знаем открытый ключ этих учетных записей, и поэтому Anchor заключает объект учетной записи в другой объект, чтобы дать нам больше контекста. Вот почему мы получаем доступ к данным учетной записи через tweetAccount.account.
Вот небольшая диаграмма, чтобы обобщить это.
Фильтрация твитов по теме
Фильтрация твитов по теме очень похожа на фильтрацию твитов по автору. Нам по-прежнему нужен фильтр memcpm, но с другими параметрами.
Начнем со смещения. Опять же, если мы посмотрим на то, как структурирована наша учетная запись Tweet, мы увидим, что тема начинается с 52-го байта.
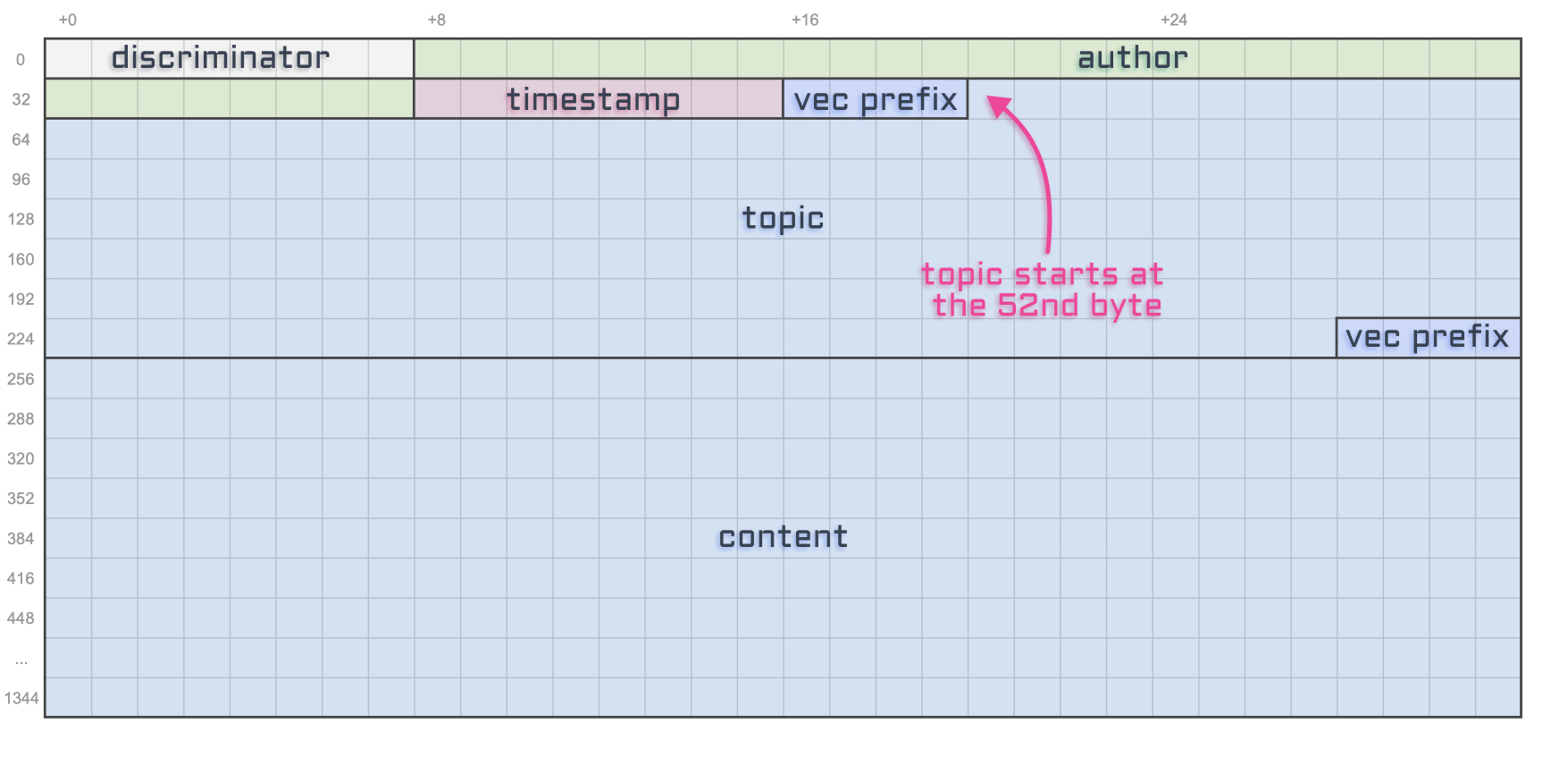
Это потому, что у нас есть 8 байтов для дискриминатора, 32 байта для автора, 8 байтов для метки времени и дополнительные 4 байта для «префикса строки», который сообщает нам реальную длину нашей темы в байтах.
Итак, давайте добавим эти числа явно в фильтр memcmp, чтобы его было легче поддерживать в будущем.
const tweetAccounts = await program.account.tweet.all([
{
memcmp: {
offset: 8 + // Discriminator.
32 + // Author public key.
8 + // Timestamp.
4, // Topic string prefix.
bytes: '', // TODO
}
}
]);
Далее нам нужно указать тему для поиска в наших тестах. Поскольку две из трех учетных записей, созданных в ходе тестов, используют тему veganism, давайте воспользуемся ею.
Тем не менее, мы не можем просто указать 'veganism' в виде строки для свойства bytes. Это должен быть массив байтов в кодировке base-58. Для этого нам сначала нужно преобразовать нашу строку в буфер, который мы затем можем закодировать в базе 58.
- Мы можем преобразовать строку в буфер, используя
Buffer.from('some string'). - Мы можем кодировать буфер в base-58, используя
bs58.encode(buffer).
Переменная Buffer уже доступна глобально, но это не относится к переменной bs58, которую нам нужно явно импортировать в начале нашего тестового файла.
import * as anchor from '@project-serum/anchor';
import { Program } from '@project-serum/anchor';
import { SolanaTwitter } from '../target/types/solana_twitter';
import * as assert from "assert";
import * as bs58 from "bs58";
Итак, теперь мы можем, наконец, заполнить свойство bytes нашей темой veganism, закодированной в base-58.
const tweetAccounts = await program.account.tweet.all([
{
memcmp: {
offset: 8 + // Discriminator.
32 + // Author public key.
8 + // Timestamp.
4, // Topic string prefix.
bytes: bs58.encode(Buffer.from('veganism')),
}
}
]);
Как и в нашем предыдущем тесте, давайте создадим новый тест, который утверждает, что tweetAccounts содержит только две учетные записи и что обе они имеют тему veganism .
it('can filter tweets by topics', async () => {
const tweetAccounts = await program.account.tweet.all([
{
memcmp: {
offset: 8 + // Discriminator.
32 + // Author public key.
8 + // Timestamp.
4, // Topic string prefix.
bytes: bs58.encode(Buffer.from('veganism')),
}
}
]);
assert.equal(tweetAccounts.length, 2);
assert.ok(tweetAccounts.every(tweetAccount => {
return tweetAccount.account.topic === 'veganism'
}))
});
Вывод
Получение и фильтрация нескольких учетных записей твитов... Проверьте! ✅
Поздравляем, теперь у вас есть полностью протестированная программа Solana! Теперь мы можем потратить оставшееся время на реализацию клиента JavaScript для нашей программы, с которым могут взаимодействовать наши пользователи. К счастью, поскольку мы так многому научились, написав тесты, это покажется вам очень знакомым.
Просмотреть эпизод 6 на GitHub
Увидимся в следующем эпизоде, где мы начнем формировать наше приложение VueJS. Пойдем!